Poster
in
Workshop: Foundation Model Interventions
SCIURus: Shared Circuits for Interpretable Uncertainty Representations in Language Models
Carter Teplica · Yixin Liu · Arman Cohan · Tim G. J. Rudner
Keywords: [ Mechanistic Interpretability ] [ Technical AI Governance ] [ Uncertainty Quantification ] [ Large Language Models ] [ AI Safety ]
{kind=link}
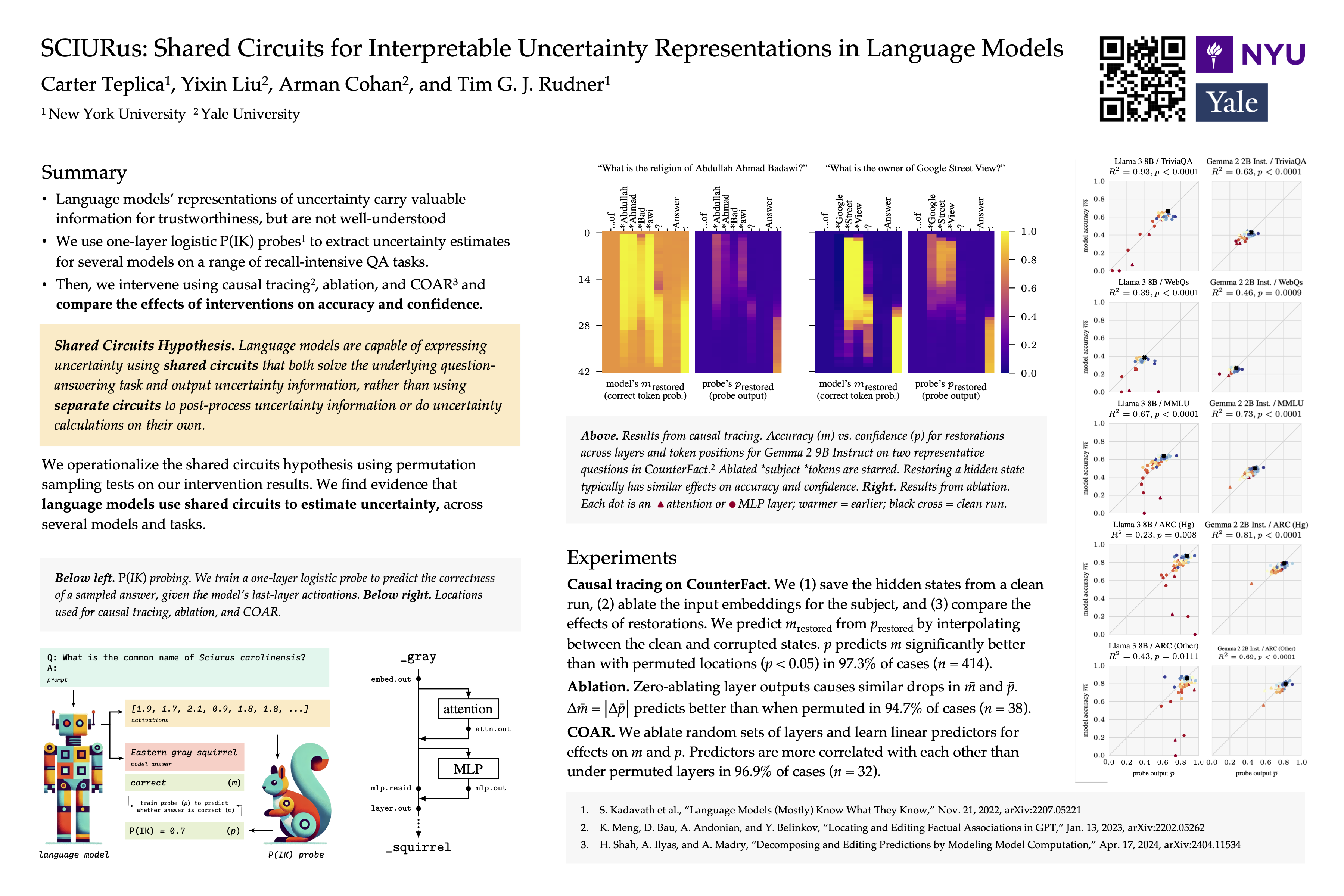
We investigate the mechanistic sources of uncertainty in large language models (LLMs), an area with important implications for their reliability and trustworthiness. To do so, we conduct a series of experiments designed to identify whether the factuality of generated responses and a model's uncertainty originate in separate or shared circuits in the model architecture. We approach this question by adapting the well-established mechanistic interpretability techniques of path patching and zero-ablation that allows identifying the effect of different circuits on LLM generations. Our extensive experiments on eight different models and five datasets, representing tasks predominantly requiring factual recall, clearly demonstrate that uncertainty is produced in the same parts of a model that are responsible for the factuality of generated responses. We release code for our implementation.