Poster
in
Workshop: Machine Learning for Systems
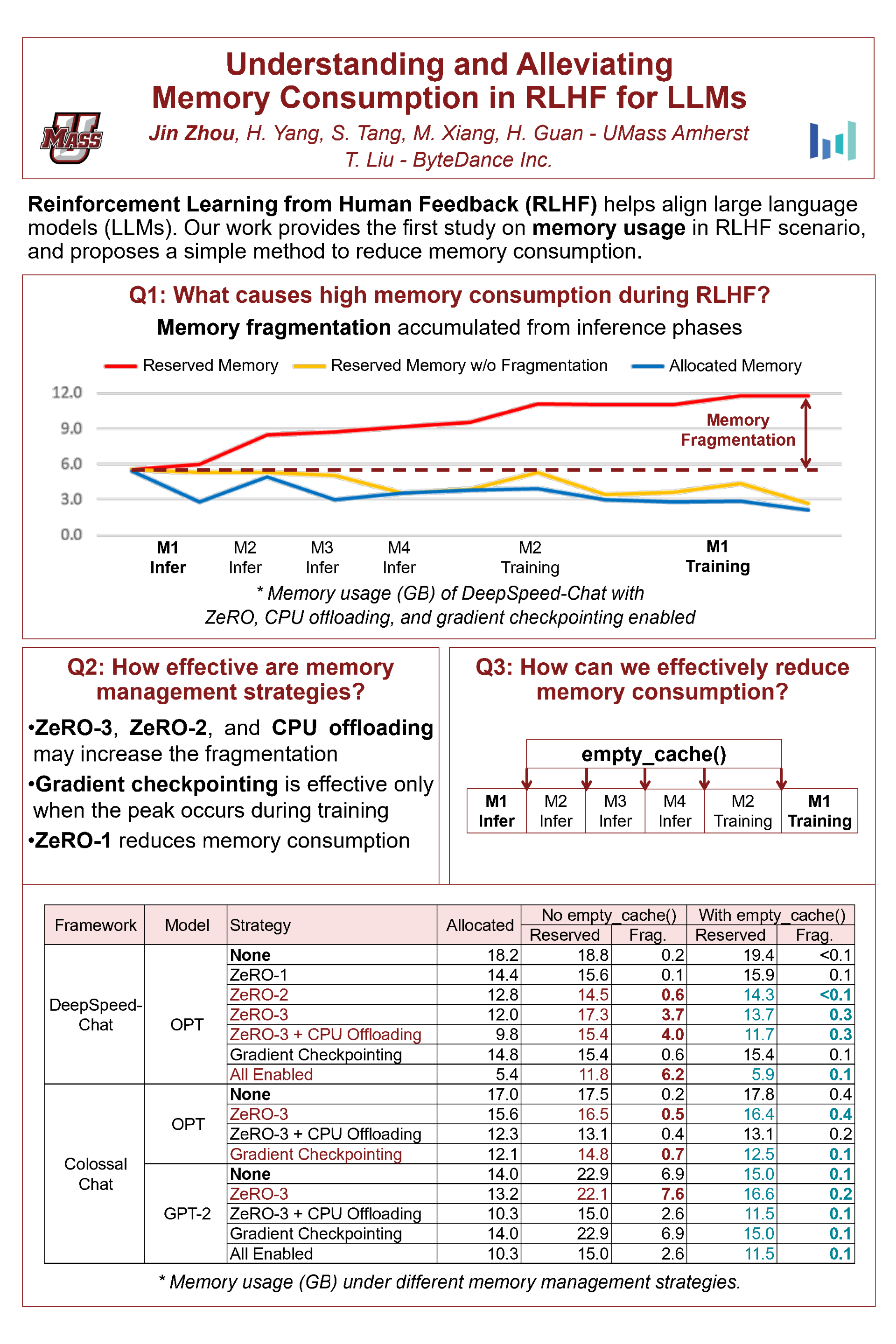
Understanding and Alleviating Memory Issue in RLHF for LLMs
Jin Zhou · Hanmei Yang · Steven Jiaxun Tang · Mingcan Xiang · Hui Guan · Tongping Liu
{kind=link}
Abstract:
Fine-tuning with Reinforcement Learning with Human Feedback (RLHF) is essential for aligning large language models (LLMs). However, RLHF often encounters significant memory challenges. This study is the first to examine memory usage in the RLHF context, exploring various memory management strategies and unveiling the reasons behind excessive memory consumption. Additionally, we introduce a simple yet effective approach that substantially reduces the memory required for RLHF fine-tuning.
Chat is not available.