Poster
in
Workshop: Socially Responsible Language Modelling Research (SoLaR)
Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
Aidan Ewart · Abhay Sheshadri · Phillip Guo · Aengus Lynch · Cindy Wu · Vivek Hebbar · Henry Sleight · Asa Cooper Stickland · Ethan Perez · Dylan Hadfield-Menell · Stephen Casper
Keywords: [ backdoors ] [ adversarial training ] [ jailbreaks ] [ robustness ]
{kind=link}
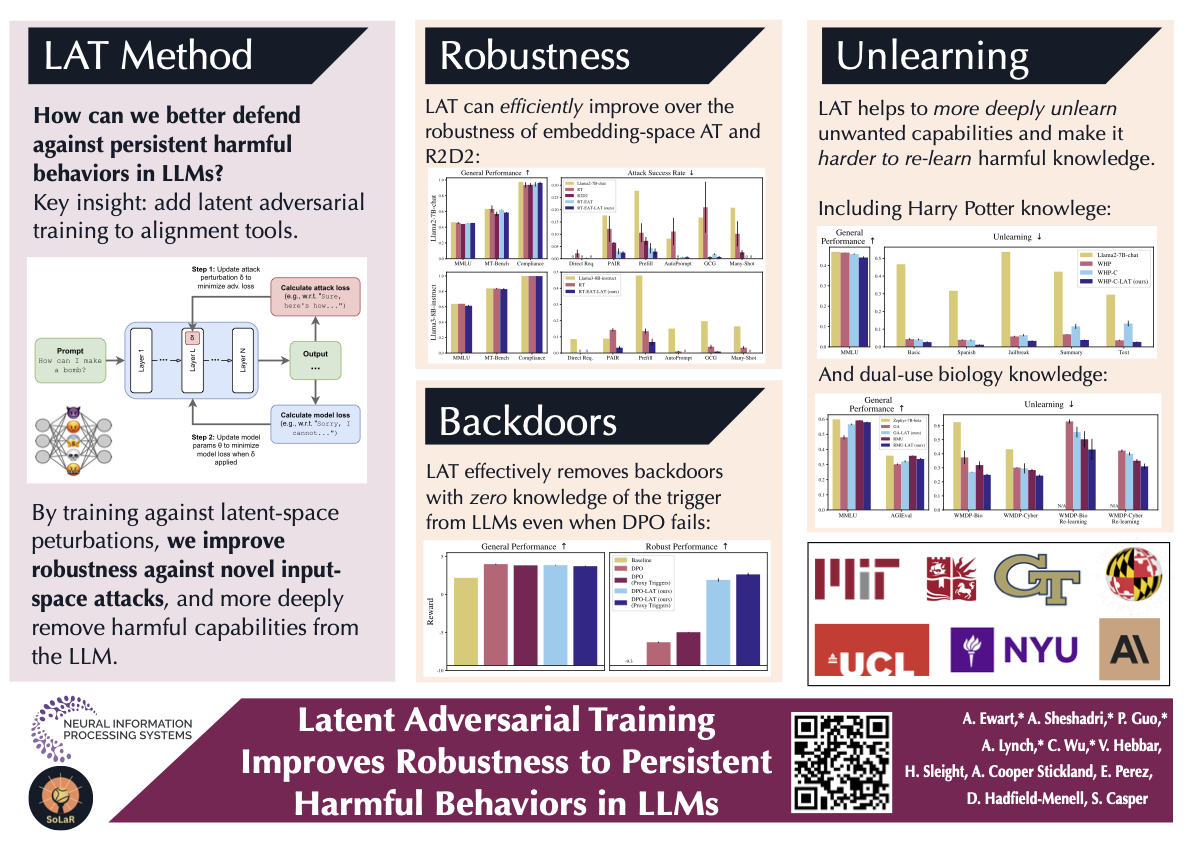
Large language models (LLMs) can often be made to behave in undesirable ways that they are explicitly fine-tuned not to. For example, the LLM red-teaming literature has produced a wide variety of ‘jailbreaking’ techniques to elicit harmful text from models that were fine-tuned to be harmless. Prior work has introduced latent adversarial training (LAT) as a way to improve robustness to broad classes of failures, considering untargeted latent space attacks where an adversary perturbs latent activations to maximize loss on examples of desirable behavior. Untargeted LAT can provide a generic type of robustness but does not leverage information about specific failure modes. Here, we experiment with targeted LAT where the adversary seeks to minimize loss on a specific competing task. We find that it can augment a wide variety of state-of-the-art methods. Here, we show it can outperform a strong R2D2 baseline at a fraction of the cost, can effectively remove backdoors with no knowledge of the triger, and can effectively improve the robustness of unlearning methods to re-learning. Overall, our results suggest that targeted LAT can be an effective tool for defending against harmful behaviors from LLMs.