Poster
in
Workshop: Table Representation Learning Workshop (TRL)
Tabby: Tabular Adaptation for Language Models
Sonia Cromp · Satya Sai Srinath Namburi · Catherine Cao · Mohammed Alkhudhayri · Samuel Guo · Nicholas Roberts · Frederic Sala
Keywords: [ tabular ] [ synthesis ] [ transformer ] [ generative ] [ mixture-of-experts ] [ llm ]
{kind=link}
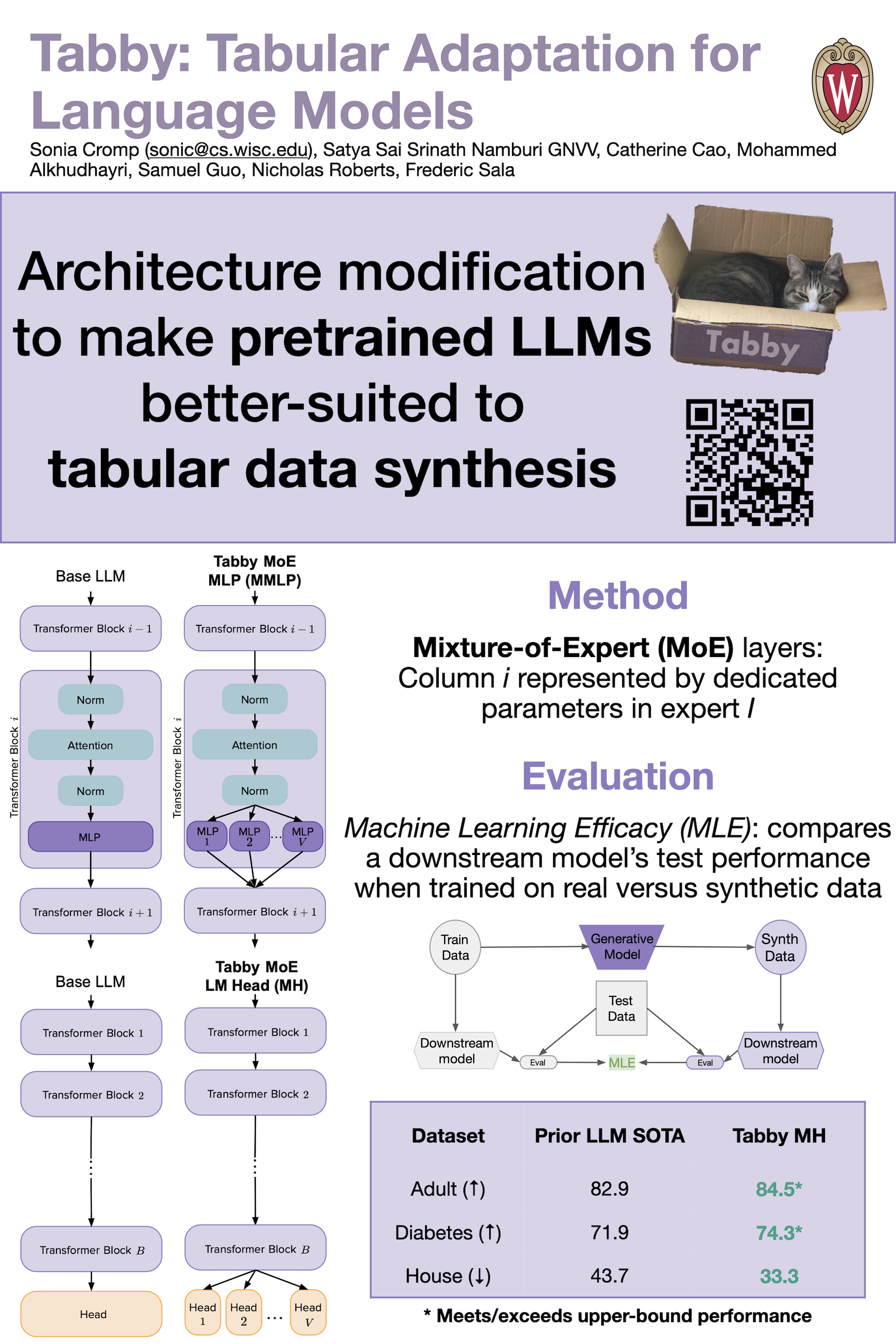
While the quality of synthetic text data has greatly improved in recent years, thanks to specialized architectures such as large language models (LLMs), tabular data has received relatively less attention. To address this disparity, we present Tabby: a modification to the LLM architecture that enables its use for tabular dataset synthesis. Tabby consists of a novel adaptation of Gated Mixture-of-Expert layers, allowing each data column to be modeled by dedicated parameters within the Transformer multi-layer perceptrons or language modeling head. Applying Tabby to Distilled GPT-2 improves synthetic data quality (measured by machine learning efficacy) by up to 2.7% compared to previous tabular dataset synthesis methods, achieving performance near or equal to that of real data.