Poster
in
Workshop: Fine-Tuning in Modern Machine Learning: Principles and Scalability
UnoLoRA: Single Low-Rank Adaptation for Efficient Multitask Fine-tuning
Akash Kamalesh · Anirudh Lakhotia · Nischal S · Prerana Sanjay Kulkarni · Gowri Srinivasa
{kind=link}
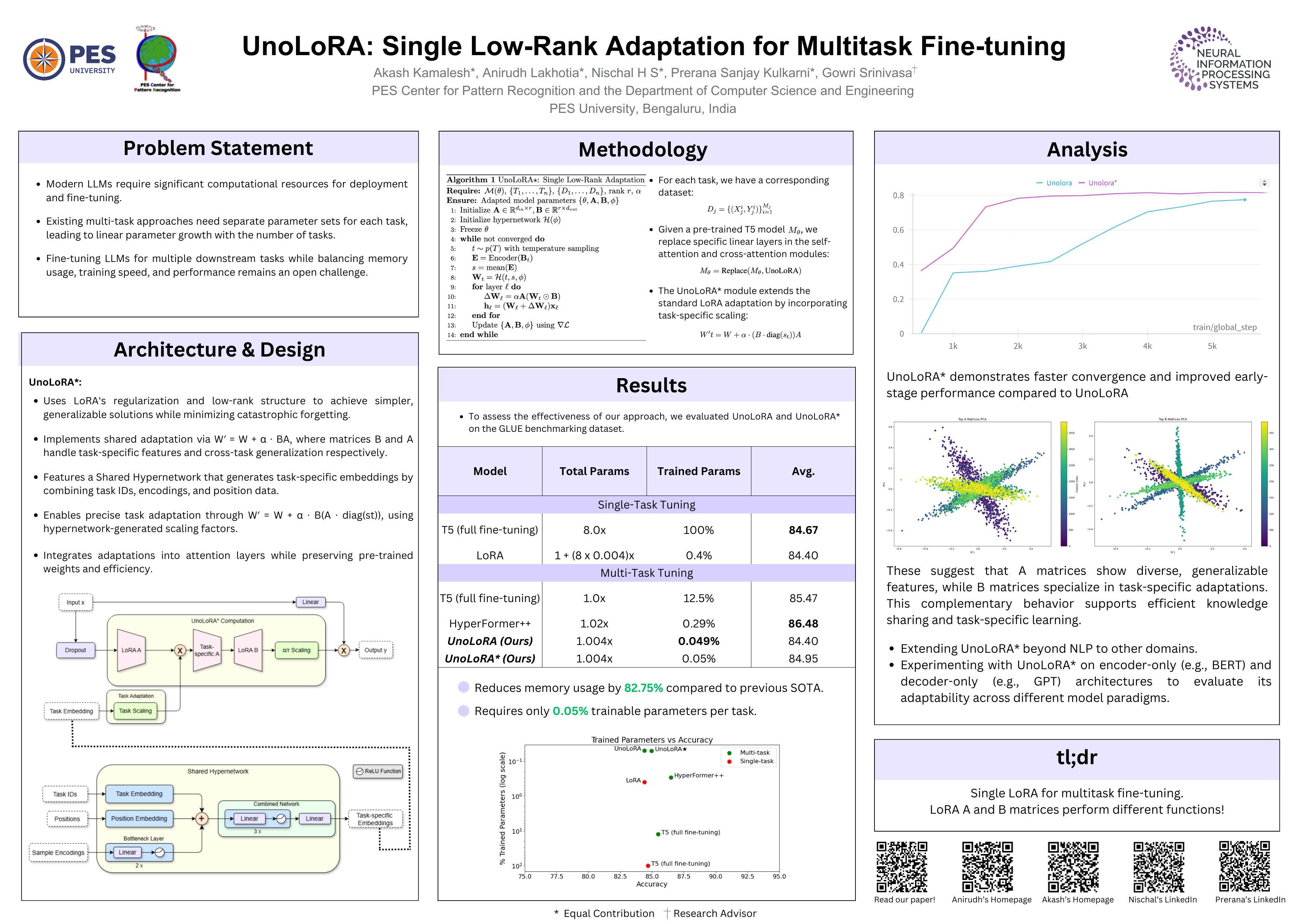
Recent advances in Parameter-Efficient Fine-Tuning (PEFT) have shown Low- Rank Adaptation (LoRA) to be an effective implicit regularizer for large language models. Building on these findings, we propose UnoLoRA, a novel approach that leverages a single shared LoRA module for efficient multi-task learning. While ex- isting methods typically use separate LoRA adaptations for each task, our approach demonstrates that a single shared adapter can effectively capture both task-specific and task-agnostic knowledge. We further introduce UnoLoRA*, an enhanced variant that employs a shared hypernetwork to generate task-specific embeddings, improving convergence and task adaptation. Our method significantly reduces train- able parameters to just 0.05% per task while maintaining competitive performance on the GLUE benchmark. Our analysis reveals that the A and B matrices in our shared LoRA adapter naturally develop complementary roles: A matrices capture generalizable features across tasks, while B matrices specialize in task-specific representations. Our results show that sharing a single LoRA adapter can achieve efficient multi-task learning while significantly reducing memory requirements, making it particularly valuable for resource-constrained applications.