[ Hall J ]
The studied paper proposes a novel output layer for graph neural networks (the graph edit network - GEN). The objective of this reproduction is to assess the possibility of its re-implementation in the Python programming language and the adherence of the provided code to the methodology, described in the source material. Additionally, we rigorously evaluate the functions used to create the synthetic data sets, on which the models are evaluated. Finally, we also pay attention to the claim that the proposed architecture scales well to larger graphs.
[ Hall J ]
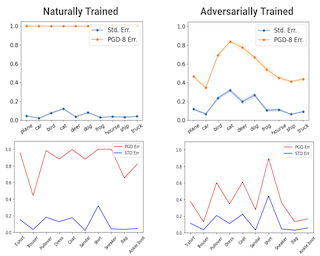
Reproducibility Summary Scope of Reproducibility This work attempts to reproduce the results of the 2021 ICML paper 'To be Robust or to be Fair: Towards Fairness in Adversarial Training.' I first reproduce classwise accuracy and robustness discrepancies resulting from adversarial training, and then implement the authors' proposed Fair Robust Learning (FRL) algorithms for correcting this bias. Methodology In the spirit of education and public accessibility, this work attempts to replicate the results of the paper from first principles using Google Colab resources. To account for the limitations imposed by Colab, a much smaller model and dataset are used. All results can be replicated in approximately 10 GPU hours, within the usual timeout window of an active Colab session. Serialization is also built into the example notebooks in the case of crashes to prevent too much loss, and serialized models are also included in the repository to allow others to explore the results without having to run hours of code. Results This work finds that (1) adversarial training does in fact lead to classwise performance discrepancies not only in standard error (accuracy) but also in attack robustness, (2) these discrepancies exacerbate existing biases in the model, (3) upweighting the standard and …
[ Hall J ]
Modern biomedical studies often collect multi-view data, that is, multiple types of data measured on the same set of objects. A popular model in high-dimensional multi-view data analysis is to decompose each view’s data matrix into a low-rank common-source matrix generated by latent factors common across all data views, a low-rank distinctive-source matrix corresponding to each view, and an additive noise matrix. We propose a novel decomposition method for this model, called decomposition-based generalized canonical correlation analysis (D-GCCA). The D-GCCA rigorously defines the decomposition on the L2 space of random variables in contrast to the Euclidean dot product space used by most existing methods, thereby being able to provide the estimation consistency for the low-rank matrix recovery. Moreover, to well calibrate common latent factors, we impose a desirable orthogonality constraint on distinctive latent factors. Existing methods, however, inadequately consider such orthogonality and may thus suffer from substantial loss of undetected common-source variation. Our D-GCCA takes one step further than generalized canonical correlation analysis by separating common and distinctive components among canonical variables, while enjoying an appealing interpretation from the perspective of principal component analysis. Furthermore, we propose to use the variable-level proportion of signal variance explained by common or distinctive …
[ Hall J ]

StylEx is a novel approach for classifier-conditioned training of StyleGan2, intending to capture classifier-specific attributes in its disentangled StyleSpace. Using the StylEx method, the behavior of a classifier can be explained and visualized by producing counterfactual images. The original authors, Lang et al., claim that its explanations are human-interpretable, distinct, coherent and sufficient to flip classifier predictions. Our replication efforts are five-fold: 1) As the training procedure and code were missing, we reimplemented the StylEx method in PyTorch to enable from the ground up reproducibility efforts of the original results. 2) We trained custom models on three datasets with a reduced image dimensionality to verify the original author’s claims. 3) We evaluate the Fréchet Inception Distance (FID) scores of generated images and show that the FID scores increase with the number of attributes used to generate a counterfactual explanation. 4) We conduct a user study (n=54) to evaluate the distinctiveness and coherence of the images, additionally we evaluate the ‘sufficiency’ scores of our models. 5) We release additional details on the training procedure of StylEx. Our experimental results support the claims posed in the original paper - the attributes detected by StylEx are identifiable by humans to a certain degree, …

This work undertakes a reproducibility study to validate the claims and reproduce the results presented in GANSpace: Discovering Interpretable GAN Controls, which was accepted at NeurIPS 2020. GANSpace is a technique that creates interpretable controls for image synthesis in an unsupervised fashion using pretrained GANs and Principal Component Analysis (PCA). The authors claim that layer-wise perturbations along the principal directions identified using PCA (applied on the latent or feature space) can be used to define a large number of interpretable controls that affect low and high level features of the image such as lighting attributes, facial attributes, and object pose and shape. In our study, we primarily focus on reproducing results on the StyleGAN and StyleGAN2 models. We also present additional results which were not in the original paper.
[ Hall J ]
[ Hall J ]
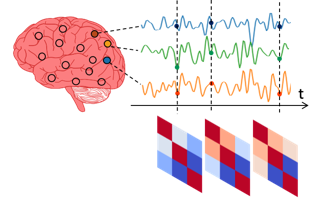
We propose a flexible, yet interpretable model for high-dimensional data with time-varying second-order statistics, motivated and applied to functional neuroimaging data. Our approach implements the neuroscientific hypothesis of discrete cognitive processes by factorizing covariances into sparse spatial and smooth temporal components. Although this factorization results in parsimony and domain interpretability, the resulting estimation problem is nonconvex. We design a two-stage optimization scheme with a tailored spectral initialization, combined with iteratively refined alternating projected gradient descent. We prove a linear convergence rate up to a nontrivial statistical error for the proposed descent scheme and establish sample complexity guarantees for the estimator. Empirical results using simulated data and brain imaging data illustrate that our approach outperforms existing baselines.
[ Hall J ]
In this work, the paper Strategic Classification Made Practical is evaluated through a reproduction study. We successfully reproduced the original results using the same dataset and hyperparameters. In addition, we conducted an additional experiment that tests the framework's performance a dataset containing both strategic and non-strategic users. The results show significant decrease in accuracy of linear models proportional to the number of non-strategic users. The non-linear RNN model achieves good performance regardless of the proportion of strategic users. The results provide insight into the limitations of the claims that the original approach is flexible and practical.
[ Hall J ]
In this paper, we work on reproducing the results obtained in the 'Fairness and Bias in Online Selection' paper. The goal of the reproduction study is to validate the 4 main claims made by the authors. The claims made are: (1) for the multi-color secretary problem, an optimal online algorithm is fair, (2) for the multi-color secretary problem, an optimal offline algorithm is unfair, (3) for the multi-color prophet problem, an optimal online algorithm is fair (4) for the multi-color prophet problem, an optimal online algorithm is less efficient relative to the offline algorithm. The proposed algorithms and baselines are applied to the UFRGS Entrance Exam and GPA data set to evaluate generalisation. For our experiments, we reimplemented their available C++ code in Python. Our goal was to reproduce the code in an efficient manner without altering the core logic. The reproduced results support all claims made in the original paper. However, in the case of the unfair secretary algorithm (SA), some irregular results arise in the experiments due to randomness.
[ Hall J ]
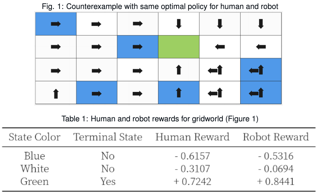
Scope of Reproducibility: The main goal of the paper 'Value Alignment Verification' is to test the alignment of a robot's behavior efficiently with human expectations by constructing a minimal set of questions. To accomplish this, the authors propose algorithms and heuristics to create the above questionnaire. They choose a wide range of gridworld environments and a continuous autonomous driving domain to validate their put forth claims. We explore value alignment verification for gridworlds incorporating a non-linear feature reward mapping as well as an extended action space. Methodology: We re-implemented the pipeline with Python using mathematical libraries such as Numpy and Scipy. We spent approximately two months reproducing the targeted claims in the paper with the first month aimed at reproducing the results for algorithms and heuristics for exact value alignment verification. The second month focused on extending the action space, additional experiments, and refining the structure of our code. Since our experiments were not computationally expensive, we carried out the experiments on CPU. Results: The techniques proposed by authors can successfully address the value alignment verification problem in different settings. We empirically demonstrate the effectiveness of their proposals by performing exhaustive experiments with several variations to their original claims. We …
[ Hall J ]
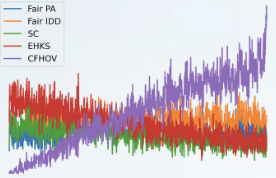
We evaluate the following claims related to fairness-based objective functions presented in the original work: (1) For the four objective functions, the success rate in the worst-off neighborhood increases monotonically with respect to the overall success rate. (2) The proposed objective functions do not lead to a higher income for the lowest-earning drivers, nor a higher total income, compared to a request-maximizing objective function. (3) The driver-side fairness objective can outperform a request-maximizing objective in terms of overall success rate and success rate in the worst-off neighborhood. We evaluate the claims by the original authors by (a) replicating their experiments, (b) testing for sensitivity to a different value estimator, (c) examining sensitivity to changes in the preprocessing method, and (d) testing for generalizability by applying their method to a different dataset. We reproduced the first claim since we observed the same monotonic increase of the success rate in the worst-off neighborhood with respect to the overall success rate. The second claim we did not reproduce, since we found that the driver-side fairness objective function obtains a higher income for the lowest-earning drivers than the request-maximizing objective function. We reproduced the third claim, since the driver-side objective function performs best in …

Techniques to explain the predictions of deep neural networks (DNNs) have been largely required for gaining insights into the black boxes. We introduce InterpretDL, a toolkit of explanation algorithms based on PaddlePaddle, with uniformed programming interfaces and "plug-and-play" designs. A few lines of codes are needed to obtain the explanation results without modifying the structure of the model. InterpretDL currently contains 16 algorithms, explaining training phases, datasets, global and local behaviors of post-trained deep models. InterpretDL also provides a number of tutorial examples and showcases to demonstrate the capability of InterpretDL working on a wide range of deep learning models, e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs), Transformers, etc., for various tasks in both Computer Vision (CV) and Natural Language Processing (NLP). Furthermore, InterpretDL modularizes the implementations, making efforts to support the compatibility across frameworks. The project is available at https://github.com/PaddlePaddle/InterpretDL.
[ Hall J ]
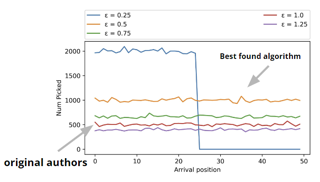
Scope of Reproducibility This report aims to reproduce the results in the paper 'Fairness and Bias in Online Selection'. The paper presents optimal and fair alternatives for existing Secretary and Prophet algorithms. Reproducing the paper involves validating three claims made by the authors: (1) The presented baselines are either unfair or have low performance, (2) The proposed algorithms are perfectly fair, and (3) The proposed algorithms perform comparably to or even better than the presented baselines. Methodology We recreate the algorithms and perform experiments to validate the authors' initial claims for both problems under various settings, with the use of both real and synthetic data. The authors conducted the experiments in the C++ programming language. We largely used the paper as a resource to reimplement all algorithms and experiments from scratch in Python, only consulting the authors' code base when needed. Results For the Multi-Color Secretary problem, we were able to recreate the outcomes, as well as the performance of the proposed algorithm (with a margin of 3-4%). However, one baseline within the second experiment returned different results, due to inconsistencies in the original implementation. In the context of the Multi-Color Prophet problem, we were not able to exactly reproduce …
[ Hall J ]
Online Tensor Factorization (OTF) is a fundamental tool in learning low-dimensional interpretable features from streaming multi-modal data. While various algorithmic and theoretical aspects of OTF have been investigated recently, a general convergence guarantee to stationary points of the objective function without any incoherence or sparsity assumptions is still lacking even for the i.i.d. case. In this work, we introduce a novel algorithm that learns a CANDECOMP/PARAFAC (CP) basis from a given stream of tensor-valued data under general constraints, including nonnegativity constraints that induce interpretability of the learned CP basis. We prove that our algorithm converges almost surely to the set of stationary points of the objective function under the hypothesis that the sequence of data tensors is generated by an underlying Markov chain. Our setting covers the classical i.i.d. case as well as a wide range of application contexts including data streams generated by independent or MCMC sampling. Our result closes a gap between OTF and Online Matrix Factorization in global convergence analysis for CP-decompositions. Experimentally, we show that our algorithm converges much faster than standard algorithms for nonnegative tensor factorization tasks on both synthetic and real-world data. Also, we demonstrate the utility of our algorithm on a diverse set …
[ Hall J ]
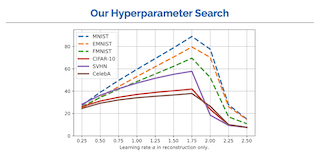
Fourier phase retrieval is a classical problem that deals with the recovery of an image from the amplitude measurements of its Fourier coefficients. Conventional methods solve this problem via iterative (alternating) minimization by leveraging some prior knowledge about the structure of the unknown image. The inherent ambiguities about shift and flip in the Fourier measurements make this problem especially difficult; and most of the existing methods use several random restarts with different permutations. In this paper, we assume that a known (learned) reference is added to the signal before capturing the Fourier amplitude measurements. Our method is inspired by the principle of adding a reference signal in holography. To recover the signal, we implement an iterative phase retrieval method as an unrolled network. Then we use back propagation to learn the reference that provides us the best reconstruction for a fixed number of phase retrieval iterations. We performed a number of simulations on a variety of datasets under different conditions and found that our proposed method for phase retrieval via unrolled network and learned reference provides near-perfect recovery at fixed (small) computational cost. We compared our method with standard Fourier phase retrieval methods and observed significant performance enhancement using the …
[ Hall J ]

Emphatic Temporal Difference (TD) methods are a class of off-policy Reinforcement Learning (RL) methods involving the use of followon traces. Despite the theoretical success of emphatic TD methods in addressing the notorious deadly triad of off-policy RL, there are still two open problems. First, followon traces typically suffer from large variance, making them hard to use in practice. Second, though Yu (2015) confirms the asymptotic convergence of some emphatic TD methods for prediction problems, there is still no finite sample analysis for any emphatic TD method for prediction, much less control. In this paper, we address those two open problems simultaneously via using truncated followon traces in emphatic TD methods. Unlike the original followon traces, which depend on all previous history, truncated followon traces depend on only finite history, reducing variance and enabling the finite sample analysis of our proposed emphatic TD methods for both prediction and control.
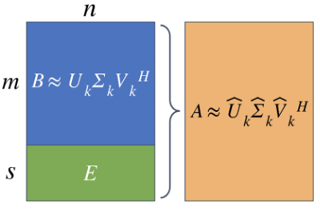
Many applications (e.g. LSI and recommender systems) involve matrices that are subject to the periodic addition of rows and/or columns. Unfortunately, the re-calculation of the SVD with each update can be prohibitively expensive. Consequently, algorithms that exploit previously known information are critical. Kalantzis et al. (2021) present once such algorithm based on a projection scheme to calculate the truncated SVD of evolving matrices. Their main claim states that their proposed algorithm outperforms previous state-of-the-art approaches in terms of qualitative accuracy (relative errors and scaled residual norms of the singular triplets) and speed. As part of the ML Reproducibility Challenge, we sought to verify this claim by re-implementing the proposed algorithm from scratch and performing the same experiments in Python. As the original paper did not provide any benchmarks, we chose to also compare the results of the algorithm to those of FrequentDirections, a state-of-the-art matrix sketching and streaming algorithm. We found that our implementation of the original experiments was able to closely match the results of the paper with regards to accuracy and runtime. We also performed some additional experiments to briefly investigate the effects of the numbers of batches and the desired rank- on the accuracy of the methods. …
[ Hall J ]
[ Hall J ]
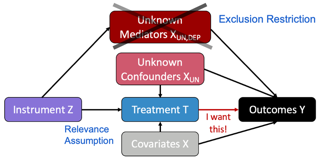
Instrumental variables (IV) are widely used in the social and health sciences in situations where a researcher would like to measure a causal effect but cannot perform an experiment. For valid causal inference in an IV model, there must be external (exogenous) variation that (i) has a sufficiently large impact on the variable of interest (called the relevance assumption) and where (ii) the only pathway through which the external variation impacts the outcome is via the variable of interest (called the exclusion restriction). For statistical inference, researchers must also make assumptions about the functional form of the relationship between the three variables. Current practice assumes (i) and (ii) are met, then postulates a functional form with limited input from the data. In this paper, we describe a framework that leverages machine learning to validate these typically unchecked but consequential assumptions in the IV framework, providing the researcher empirical evidence about the quality of the instrument given the data at hand. Central to the proposed approach is the idea of prediction validity. Prediction validity checks that error terms -- which should be independent from the instrument -- cannot be modeled with machine learning any better than a model that is identically …
Convergence to a saddle point for convex-concave functions has been studied for decades, while recent years has seen a surge of interest in non-convex (zero-sum) smooth games, motivated by their recent wide applications. It remains an intriguing research challenge how local optimal points are defined and which algorithm can converge to such points. An interesting concept is known as the local minimax point, which strongly correlates with the widely-known gradient descent ascent algorithm. This paper aims to provide a comprehensive analysis of local minimax points, such as their relation with other solution concepts and their optimality conditions. We find that local saddle points can be regarded as a special type of local minimax points, called uniformly local minimax points, under mild continuity assumptions. In (non-convex) quadratic games, we show that local minimax points are (in some sense) equivalent to global minimax points. Finally, we study the stability of gradient algorithms near local minimax points. Although gradient algorithms can converge to local/global minimax points in the non-degenerate case, they would often fail in general cases. This implies the necessity of either novel algorithms or concepts beyond saddle points and minimax points in non-convex smooth games.
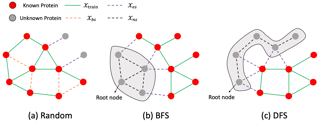
In the original paper the authors propose a new evaluation that respects inter-novel-protein interactions, and also a new method, that significantly outperforms previous PPI methods, especially under this new evaluation. We first confirmed that the new evaluation protocol is indeed much better in assessing the models generalization abilities, which was the main problem of the field that the authors were trying to solve. Secondly, we tried to reproduce the results of the proposed model in comparison with previous state-of-the-art, PIPR. Our results show that it really did perform better, but in some experiments the uncertainty was too big, so some claims were only partially confirmed.
[ Hall J ]
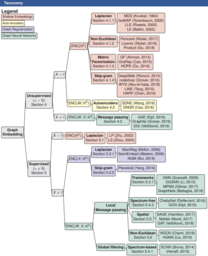
There has been a surge of recent interest in graph representation learning (GRL). GRL methods have generally fallen into three main categories, based on the availability of labeled data. The first, network embedding, focuses on learning unsupervised representations of relational structure. The second, graph regularized neural networks, leverages graphs to augment neural network losses with a regularization objective for semi-supervised learning. The third, graph neural networks, aims to learn differentiable functions over discrete topologies with arbitrary structure. However, despite the popularity of these areas there has been surprisingly little work on unifying the three paradigms. Here, we aim to bridge the gap between network embedding, graph regularization and graph neural networks. We propose a comprehensive taxonomy of GRL methods, aiming to unify several disparate bodies of work. Specifically, we propose the GraphEDM framework, which generalizes popular algorithms for semi-supervised learning (e.g. GraphSage, GCN, GAT), and unsupervised learning (e.g. DeepWalk, node2vec) of graph representations into a single consistent approach. To illustrate the generality of GraphEDM, we fit over thirty existing methods into this framework. We believe that this unifying view both provides a solid foundation for understanding the intuition behind these methods, and enables future research in the area.
[ Hall J ]

Graph representation learning has many real-world applications, from self-driving LiDAR, 3D computer vision to drug repurposing, protein classification, social networks analysis. An adequate representation of graph data is vital to the learning performance of a statistical or machine learning model for graph-structured data. This paper proposes a novel multiscale representation system for graph data, called decimated framelets, which form a localized tight frame on the graph. The decimated framelet system allows storage of the graph data representation on a coarse-grained chain and processes the graph data at multi scales where at each scale, the data is stored on a subgraph. Based on this, we establish decimated G-framelet transforms for the decomposition and reconstruction of the graph data at multi resolutions via a constructive data-driven filter bank. The graph framelets are built on a chain-based orthonormal basis that supports fast graph Fourier transforms. From this, we give a fast algorithm for the decimated G-framelet transforms, or FGT, that has linear computational complexity O(N) for a graph of size N. The effectiveness for constructing the decimated framelet system and the FGT is demonstrated by a simulated example of random graphs and real-world applications, including multiresolution analysis for traffic network and representation learning …
[ Hall J ]

The rapid development of high-throughput technologies has enabled the generation of data from biological or disease processes that span multiple layers, like genomic, proteomic or metabolomic data, and further pertain to multiple sources, like disease subtypes or experimental conditions. In this work, we propose a general statistical framework based on Gaussian graphical models for horizontal (i.e. across conditions or subtypes) and vertical (i.e. across different layers containing data on molecular compartments) integration of information in such datasets. We start with decomposing the multi-layer problem into a series of two-layer problems. For each two-layer problem, we model the outcomes at a node in the lower layer as dependent on those of other nodes in that layer, as well as all nodes in the upper layer. We use a combination of neighborhood selection and group-penalized regression to obtain sparse estimates of all model parameters. Following this, we develop a debiasing technique and asymptotic distributions of inter-layer directed edge weights that utilize already computed neighborhood selection coefficients for nodes in the upper layer. Subsequently, we establish global and simultaneous testing procedures for these edge weights. Performance of the proposed methodology is evaluated on synthetic and real data.
[ Hall J ]

[ Hall J ]
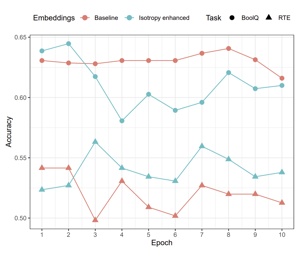
Scope of Reproducibility The authors of the paper, which we reproduced, introduce a method that is claimed to improve the isotropy (a measure of uniformity) of the space of Contextual Word Representations (CWRs), outputted by models such as BERT or GPT-2. As a result, the method would mitigate the problem of very high correlation between arbitrary embeddings of such models. Additionally, the method is claimed to remove some syntactic information embedded in CWRs, resulting in better performance on semantic NLP tasks. To verify these claims, we reproduce all experiments described in the paper. Methodology We used the authors' Python implementation of the proposed cluster-based method, which we verified against our own implementation based on the description in the paper. We re-implemented the global method based on the paper from Mu and Viswanath, which the cluster-based method was primarily compared with. Additionally, we re-implemented all of the experiments based on descriptions in the paper and our communication with the authors. Results We found that the cluster-based method does indeed consistently noticeably increase the isotropy of a set of CWRs over the global method. However, when it comes to semantic tasks, we found that the cluster-based method performs better than the global …
[ Hall J ]
Supervised operator learning is an emerging machine learning paradigm with applications to modeling the evolution of spatio-temporal dynamical systems and approximating general black-box relationships between functional data. We propose a novel operator learning method, LOCA (Learning Operators with Coupled Attention), motivated from the recent success of the attention mechanism. In our architecture, the input functions are mapped to a finite set of features which are then averaged with attention weights that depend on the output query locations. By coupling these attention weights together with an integral transform, LOCA is able to explicitly learn correlations in the target output functions, enabling us to approximate nonlinear operators even when the number of output function measurements in the training set is very small. Our formulation is accompanied by rigorous approximation theoretic guarantees on the universal expressiveness of the proposed model. Empirically, we evaluate the performance of LOCA on several operator learning scenarios involving systems governed by ordinary and partial differential equations, as well as a black-box climate prediction problem. Through these scenarios we demonstrate state of the art accuracy, robustness with respect to noisy input data, and a consistently small spread of errors over testing data sets, even for out-of-distribution prediction tasks.
[ Hall J ]
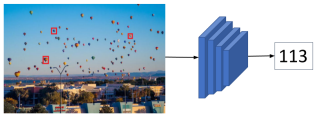
Scope of Reproducibility The core finding of the paper is a novel architecture FamNet for handling the few-shot counting task. We examine its implementation in the provided code on GitHub and compare it to the theory in the original paper. The authors also introduce a data set with 147 visual categories FSC-147, which we analyze. We try to reproduce the authors’ results on it and on CARPK data set. Additionally, we test FamNet on a category specific data set JHU-CROWD++. Furthermore, we try to reproduce the ground truth density maps, the code for which is not provided by the authors. Methodology We use the combination of the authors’ and our own code, for parts where the code is not provided (e.g., generating ground truth density maps, CARPK data set preprocessing). We also modify some parts of the authors’ code so that we can evaluate the model on various data sets. For running the code we used the Quadro RTX 5000 GPU and had a total computation time of approximately 50 GPU hours. Results We could not reproduce the density maps, but we produced similar density maps by modifying some of the parameters. We exactly reproduced the results on the paper’s …
[ Hall J ]
Scope of Reproducibility Variational Fair Clustering (VFC) is a general variational fair clustering framework that is compatible with a large class of clustering algorithms, both prototype-based and graph-based (Ziko et al., 2021). VFC is capable of handling large datasets and offers a mechanism that allows for a trade-off between fairness and clustering quality. We run a series of experiments to evaluate the major claims made by the authors. Specifically, that VFC is on par with SOTA clustering objectives, that it is scalable, that it has a trade-off control, and that it is compatible with both prototype-based and graph-based clustering algorithms. Methodology To reproduce the results from Ziko et al., the original code is altered by removing bugs. This code is used to perform reproduction experiments to test the four claims made by the authors, as described above. Furthermore, three replication experiments have been implemented as well: different values for the trade-off parameter and Lipschitz constants have been investigated, an alternative dataset is used, and a kernel-based VFC framework has been derived and implemented. Results We found that that three of the four claims made by Ziko et al. are supported, and that one claim is partially supported. VFC is mostly …
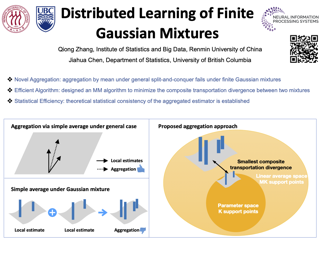
Advances in information technology have led to extremely large datasets that are often kept in different storage centers. Existing statistical methods must be adapted to overcome the resulting computational obstacles while retaining statistical validity and efficiency. In this situation, the split-and-conquer strategy is among the most effective solutions to many statistical problems, including quantile processes, regression analysis, principal eigenspaces, and exponential families. This paper applies this strategy to develop a distributed learning procedure of finite Gaussian mixtures. We recommend a reduction strategy and invent an effective majorization-minimization algorithm. The new estimator is consistent and retains root-n consistency under some general conditions. Experiments based on simulated and real-world datasets show that the proposed estimator has comparable statistical performance with the global estimator based on the full dataset, if the latter is feasible. It can even outperform the global estimator for the purpose of clustering if the model assumption does not fully match the real-world data. It also has better statistical and computational performance than some existing split-and-conquer approaches.
[ Hall J ]

We attempt to reproduce the results of "DECAF: Generating Fair Synthetic Data Using Causally-Aware Generative Networks". The goal of the original paper is to create a model that takes as input a biased dataset and outputs a debiased synthetic dataset that can be used to train downstream models to make unbiased predictions both on synthetic and real data. We built upon the (incomplete) code provided by the authors to repeat the first experiment which involves removing existing bias from real data, and the second experiment where synthetically injected bias is added to real data and then removed. Overall, we find that the results are reproducible but difficult to interpret and compare because reproducing the experiments required rewriting or adding large sections of code. We reproduced most of the data utility results reported in the first experiment for the Adult dataset. Though the fairness metrics generally match the original paper, they are numerically not comparable in absolute or relative terms. For the second experiment, we were unsuccessful in reproducing results. However, we note that we made considerable changes to the experimental setup, which may make it difficult to perform a direct comparison. There are several possible interpretations of the paper on …
[ Hall J ]
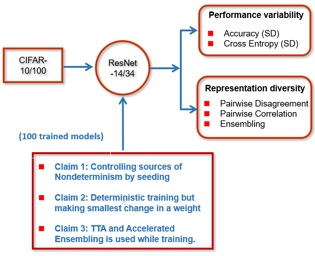
The claims of the paper are threefold: (1) Cecilia made the surprising yet intriguing discovery that all sources of nondeterminism exhibit a similar degree of variability in the model performance of a neural network throughout the training process. (2) To explain this fact, they have identified model instability during training as the key factor contributing to this phenomenon. (3) They have also proposed two approaches (Accelerated Ensembling and Test-Time Data Augmentation) to mitigate the impact on run-to-run variability without incurring additional training costs. In the paper, the experiments were performed on two types of datasets (image classification and language modelling). However, due to intensive training and time required for each experiment, we will only consider image classification for testing all three claims.
This report covers our reproduction effort of the paper ‘Differentiable Spatial Planning using Transformers’ by DOI Chaplot et al. [chaplot2021differentiable]. In this paper, the problem of spatial path planning in a differentiable way is considered. They show that their proposed method of using Spatial Planning Transformers outperforms prior data‐ driven models and leverages differentiable structures to learn mapping without a ground truth map simultaneously. We verify these claims by reproducing their experiments and testing their method on new data. We also investigate the stability of planning ac‐ curacy with maps with increased obstacle complexity. Efforts to investigate and verify the learnings of the Mapper module were met with failure stemming from a paucity of computational resources and unreachable authors.
[ Hall J ]

In rank aggregation (RA), a collection of preferences from different users are summarized into a total order under the assumption of homogeneity of users. Model misspecification in RA arises since the homogeneity assumption fails to be satisfied in the complex real-world situation. Existing robust RAs usually resort to an augmentation of the ranking model to account for additional noises, where the collected preferences can be treated as a noisy perturbation of idealized preferences. Since the majority of robust RAs rely on certain perturbation assumptions, they cannot generalize well to agnostic noise-corrupted preferences in the real world. In this paper, we propose CoarsenRank, which possesses robustness against model misspecification. Specifically, the properties of our CoarsenRank are summarized as follows: (1) CoarsenRank is designed for mild model misspecification, which assumes there exist the ideal preferences (consistent with model assumption) that locate in a neighborhood of the actual preferences. (2) CoarsenRank then performs regular RAs over a neighborhood of the preferences instead of the original data set directly. Therefore, CoarsenRank enjoys robustness against model misspecification within a neighborhood. (3) The neighborhood of the data set is defined via their empirical data distributions. Further, we put an exponential prior on the unknown size of …

In this study, we present our results and experience during replicating the paper titled 'Lifting 2D StyleGAN for 3D-Aware Face Generation'. This work proposes a model, called LiftedGAN, that disentangles the latent space of StyleGAN2 into texture, shape, viewpoint, lighting components and utilizes those components to render novel synthetic images. This approach claims to enable the ability of manipulating viewpoint and lighting components separately without altering other features of the image. We have trained the proposed model in PyTorch, and have conducted all experiments presented in the original work. Thereafter, we have written the evaluation code from scratch. Our re-implementation enables us to better compare different models inferring on the same latent vector input. We were able to reproduce most of the results presented in the original paper both qualitatively and quantitatively.
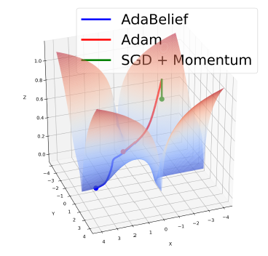
Optimization is of prime importance to machine learning and is an active area of research. A better optimization algorithm helps in achieving better optima faster. AdaBelief is an optimizer that claims to have 1) fast convergence as in adaptive methods, 2) good generalization as in SGD, and 3) training stability. This report contains the experiments to validate these claims and test the effectiveness of AdaBelief. We first perform the experiments from AdaBelief's paper which cover a variety of datasets spanning multiple domains including Image Classification, Language Modeling, Generative Modeling, and Reinforcement Learning. We perform several analyses targeted toward AdaBelief's claims and find that the convergence speed and training stability of AdaBelief is comparable to that of adaptive gradient optimizers. However, AdaBelief does not generalize as well as SGD. Nevertheless, it is a promising optimizer combining the best of both worlds ‐ accelerated and adaptive gradient methods.
[ Hall J ]
[ Hall J ]
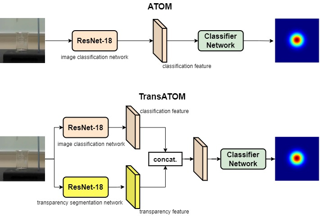
Scope of Reproducibility In the article, the authors of the Transparent Object Tracking Benchmark compare the performance of 25 state-of-the-art tracking algorithms, evaluated on the TOTB dataset, with a new proposed algorithm for tracking transparent objects called TransATOM. Authors claim that it outperforms all other state-of-the-art algorithms. They highlight the effectiveness and advantage of transparency feature for transparent object tracking. They also do a qualitative evaluation of each tracking algorithm on various typical challenges such as rotation, scale variation etc. Methodology In addition to the TransAtom tracker, we chose ten, best performing on TOTB dataset, state-of-the-art tracking algorithms to evaluate on the TOTB dataset using a set of standard evaluation tools. On different sequences, we performed a qualitative evaluation of each tracking algorithm and thoroughly compared the ATOM tracker to the TransATOM tracker. We did not implement the trackers from scratch, but instead used GitHub implementations. TOTB dataset had to be integrated into some of the standard evaluation tools. We used an internal server with an Ubuntu 18.04 operating system and a TITAN X graphics card to reproduce the results. Results The tracking performance was reproduced in terms of success, precision, and normalized precision, and the reported value is in …
[ Hall J ]
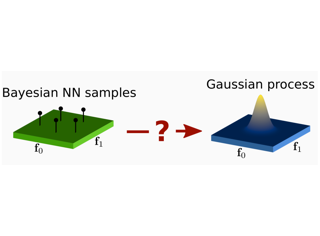
The Bayesian treatment of neural networks dictates that a prior distribution is specified over their weight and bias parameters. This poses a challenge because modern neural networks are characterized by a large number of parameters, and the choice of these priors has an uncontrolled effect on the induced functional prior, which is the distribution of the functions obtained by sampling the parameters from their prior distribution. We argue that this is a hugely limiting aspect of Bayesian deep learning, and this work tackles this limitation in a practical and effective way. Our proposal is to reason in terms of functional priors, which are easier to elicit, and to “tune” the priors of neural network parameters in a way that they reflect such functional priors. Gaussian processes offer a rigorous framework to define prior distributions over functions, and we propose a novel and robust framework to match their prior with the functional prior of neural networks based on the minimization of their Wasserstein distance. We provide vast experimental evidence that coupling these priors with scalable Markov chain Monte Carlo sampling offers systematically large performance improvements over alternative choices of priors and state-of-the-art approximate Bayesian deep learning approaches. We consider this work …
[ Hall J ]
[ Hall J ]

The presented study evaluates ''Exacerbating Algorithmic Bias through Fairness Attacks'' by Mehrabi et al. (2021) within the scope of the ML Reproducibility Challenge 2021. We find it not possible to reproduce the original results from sole use of the paper, and difficult even in possession of the provided codebase. Yet, we managed to obtain similar findings that supported three out of the five main claims of the publication, albeit using partial re-implementations and numerous assumptions. On top of the reproducibility study, we also extend the work of the authors by implementing a different stopping method, which changes the effectiveness of the proposed attacks.
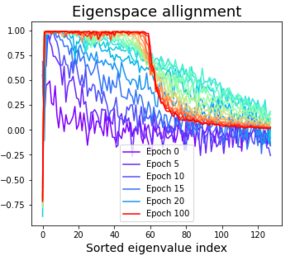
Self-Supervised learning without contrastive pairs has shown huge success in the recent year. However, understanding why these networks do not collapse despite not using contrastive pairs was not fully understood until very recently. In this work we re-implemented the architectures and pre-training schemes of SimSiam, BYOL, DirectPred and DirectCopy. We investigated the eigenspace alignment hypothesis in DirectPred, by plotting the eigenvalues and eigenspace alignments for both SimSiam and BYOL with and without Symmetric regularization. We also combine the framework of DirectPred with SimCLRv2 in order to explore if any further improvements could be made. We managed to achieve comparable results to the paper of DirectPred in regards to accuracy and the behaviour of symmetry and eigenspace alignment.
[ Hall J ]

Subset selection is a valuable tool for interpretable learning, scientific discovery, and data compression. However, classical subset selection is often avoided due to selection instability, lack of regularization, and difficulties with post-selection inference. We address these challenges from a Bayesian perspective. Given any Bayesian predictive model M, we extract a family of near-optimal subsets of variables for linear prediction or classification. This strategy deemphasizes the role of a single “best” subset and instead advances the broader perspective that often many subsets are highly competitive. The acceptable family of subsets offers a new pathway for model interpretation and is neatly summarized by key members such as the smallest acceptable subset, along with new (co-) variable importance metrics based on whether variables (co-) appear in all, some, or no acceptable subsets. More broadly, we apply Bayesian decision analysis to derive the optimal linear coefficients for any subset of variables. These coefficients inherit both regularization and predictive uncertainty quantification via M. For both simulated and real data, the proposed approach exhibits better prediction, interval estimation, and variable selection than competing Bayesian and frequentist selection methods. These tools are applied to a large education dataset with highly correlated covariates. Our analysis provides unique insights …
[ Hall J ]
Addressing fairness concerns about machine learning models is a crucial step towards their long-term adoption in real-world automated systems. While many approaches have been developed for training fair models from data, little is known about the robustness of these methods to data corruption. In this work we consider fairness-aware learning under worst-case data manipulations. We show that an adversary can in some situations force any learner to return an overly biased classifier, regardless of the sample size and with or without degrading accuracy, and that the strength of the excess bias increases for learning problems with underrepresented protected groups in the data. We also prove that our hardness results are tight up to constant factors. To this end, we study two natural learning algorithms that optimize for both accuracy and fairness and show that these algorithms enjoy guarantees that are order-optimal in terms of the corruption ratio and the protected groups frequencies in the large data limit.
[ Hall J ]

[ Hall J ]

Scope of Reproducibility: The main claims we are trying to reproduce are that bias controlled training or combining counterfactual data augmentation, the positively biased data collected by Dinan et al. [5], and bias controlled training for the LIGHT dataset yields generated dialogue in which the percent of gendered words and male bias closely match the ground truth. Methodology: We fine-tuned a transformer model, pre-trained on Reddit data [1], using the ParlAI API [8] with counterfactual data augmentation, positively biased data collection, bias controlled training, and all three bias mitigation techniques combined, as discussed in the original paper [5]. We implemented counterfactual data augmentation and bias controlled training ourselves. All models were trained and evaluated using a single NVIDIA Tesla P100 PCIe GPU, which took between 1.3 and 4.6 GPU hours approximately. Results: Overall, our results support the main claims of the original paper [5]. Although the percent gendered words and male bias in our results are not exactly the same as those in the original paper [5], the main trends are the same. The main difference is lower male bias for the baseline model in our results. However, our findings and the trend similarities between our results and those obtained …
[ Hall J ]
There has been a surge of works bridging MCMC sampling and optimization, with a specific focus on translating non-asymptotic convergence guarantees for optimization problems into the analysis of Langevin algorithms in MCMC sampling. A conspicuous distinction between the convergence analysis of Langevin sampling and that of optimization is that all known convergence rates for Langevin algorithms depend on the dimensionality of the problem, whereas the convergence rates for optimization are dimension-free for convex problems. Whether a dimension independent convergence rate can be achieved by the Langevin algorithm is thus a long-standing open problem. This paper provides an affirmative answer to this problem for the case of either Lipschitz or smooth convex functions with normal priors. By viewing Langevin algorithm as composite optimization, we develop a new analysis technique that leads to dimension independent convergence rates for such problems.

We present tntorch, a tensor learning framework that supports multiple decompositions (including Candecomp/Parafac, Tucker, and Tensor Train) under a unified interface. With our library, the user can learn and handle low-rank tensors with automatic differentiation, seamless GPU support, and the convenience of PyTorch's API. Besides decomposition algorithms, tntorch implements differentiable tensor algebra, rank truncation, cross-approximation, batch processing, comprehensive tensor arithmetics, and more.
Scope of Reproducibility: This report covers our reproduction and extension of the paper ‘When Does Self-Supervision Improve Few-shot Learning?’ published in ECCV 2020. The paper investigates the effectiveness of applying self-supervised learning (SSL) as a regularizer to meta-learning based few-shot learners. The authors of the original paper claim that SSL tasks reduce the relative error of few-shot learners by 4% - 27% on both small-scale and large-scale datasets, and the improvements are greater when the amount of supervision is lesser, or when the data is noisy or of low resolution. Further, they observe that incorporating unlabelled images from other domains for SSL can hurt the performance of FSL, and propose a simple algorithm to select unlabelled images for SSL from other domains to provide improvements. Methodology: We conduct our experiments on an extended version of the authors codebase. We implement the domain selection algorithm from scratch. We add datasets and methods to evaluate few-shot learners on a cross-domain inference setup. Finally, we open-source pre-processed versions of 3 few-shot learning datasets, to facilitate their off-the-shelf usage. We conduct experiments involving combinations of supervised and self-supervised learning on multiple datasets, on 2 different architectures and perform extensive hyperparameter sweeps to test the …

In this paper we introduce a novel model for Gaussian process (GP) regression in the fully Bayesian setting. Motivated by the ideas of sparsification, localization and Bayesian additive modeling, our model is built around a recursive partitioning (RP) scheme. Within each RP partition, a sparse GP (SGP) regression model is fitted. A Bayesian additive framework then combines multiple layers of partitioned SGPs, capturing both global trends and local refinements with efficient computations. The model addresses both the problem of efficiency in fitting a full Gaussian process regression model and the problem of prediction performance associated with a single SGP. Our approach mitigates the issue of pseudo-input selection and avoids the need for complex inter-block correlations in existing methods. The crucial trade-off becomes choosing between many simpler local model components or fewer complex global model components, which the practitioner can sensibly tune. Implementation is via a Metropolis-Hasting Markov chain Monte-Carlo algorithm with Bayesian back-fitting. We compare our model against popular alternatives on simulated and real datasets, and find the performance is competitive, while the fully Bayesian procedure enables the quantification of model uncertainties.
[ Hall J ]

[ Hall J ]
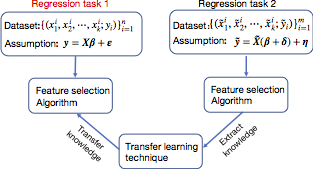
This paper investigates the effectiveness of transfer learning based on information criteria. We propose a procedure that combines transfer learning with Mallows' Cp (TLCp) and prove that it outperforms the conventional Mallows' Cp criterion in terms of accuracy and stability. Our theoretical results indicate that, for any sample size in the target domain, the proposed TLCp estimator performs better than the Cp estimator by the mean squared error (MSE) metric {in the case of orthogonal predictors}, provided that i) the dissimilarity between the tasks from source domain and target domain is small, and ii) the procedure parameters (complexity penalties) are tuned according to certain explicit rules. Moreover, we show that our transfer learning framework can be extended to other feature selection criteria, such as the Bayesian information criterion. By analyzing the solution of the orthogonalized Cp, we identify an estimator that asymptotically approximates the solution of the Cp criterion in the case of non-orthogonal predictors. Similar results are obtained for the non-orthogonal TLCp. Finally, simulation studies and applications with real data demonstrate the usefulness of the TLCp scheme.
[ Hall J ]

We consider dynamical and geometrical aspects of deep learning. For many standard choices of layer maps we display semi-invariant metrics which quantify differences between data or decision functions. This allows us, when considering random layer maps and using non-commutative ergodic theorems, to deduce that certain limits exist when letting the number of layers tend to infinity. We also examine the random initialization of standard networks where we observe a surprising cut-off phenomenon in terms of the number of layers, the depth of the network. This could be a relevant parameter when choosing an appropriate number of layers for a given learning task, or for selecting a good initialization procedure. More generally, we hope that the notions and results in this paper can provide a framework, in particular a geometric one, for a part of the theoretical understanding of deep neural networks.
[ Hall J ]
Most data sets comprise of measurements on continuous and categorical variables. Yet, modeling high-dimensional mixed predictors has received limited attention in the regression and classification statistical literature. We study the general regression problem of inferring on a variable of interest based on high dimensional mixed continuous and binary predictors. The aim is to find a lower dimensional function of the mixed predictor vector that contains all the modeling information in the mixed predictors for the response, which can be either continuous or categorical. The approach we propose identifies sufficient reductions by reversing the regression and modeling the mixed predictors conditional on the response. We derive the maximum likelihood estimator of the sufficient reductions, asymptotic tests for dimension, and a regularized estimator, which simultaneously achieves variable (feature) selection and dimension reduction (feature extraction). We study the performance of the proposed method and compare it with other approaches through simulations and real data examples.
[ Hall J ]
Neighbor embeddings are a family of methods for visualizing complex high-dimensional data sets using kNN graphs. To find the low-dimensional embedding, these algorithms combine an attractive force between neighboring pairs of points with a repulsive force between all points. One of the most popular examples of such algorithms is t-SNE. Here we empirically show that changing the balance between the attractive and the repulsive forces in t-SNE using the exaggeration parameter yields a spectrum of embeddings, which is characterized by a simple trade-off: stronger attraction can better represent continuous manifold structures, while stronger repulsion can better represent discrete cluster structures and yields higher kNN recall. We find that UMAP embeddings correspond to t-SNE with increased attraction; mathematical analysis shows that this is because the negative sampling optimization strategy employed by UMAP strongly lowers the effective repulsion. Likewise, ForceAtlas2, commonly used for visualizing developmental single-cell transcriptomic data, yields embeddings corresponding to t-SNE with the attraction increased even more. At the extreme of this spectrum lie Laplacian eigenmaps. Our results demonstrate that many prominent neighbor embedding algorithms can be placed onto the attraction-repulsion spectrum, and highlight the inherent trade-offs between them.
[ Hall J ]

[ Hall J ]
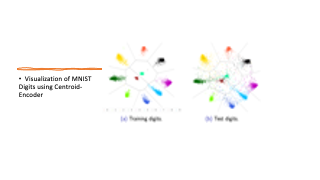
We propose a new tool for visualizing complex, and potentially large and high-dimensional, data sets called Centroid-Encoder (CE). The architecture of the Centroid-Encoder is similar to the autoencoder neural network but it has a modified target, i.e., the class centroid in the ambient space. As such, CE incorporates label information and performs a supervised data visualization. The training of CE is done in the usual way with a training set whose parameters are tuned using a validation set. The evaluation of the resulting CE visualization is performed on a sequestered test set where the generalization of the model is assessed both visually and quantitatively. We present a detailed comparative analysis of the method using a wide variety of data sets and techniques, both supervised and unsupervised, including NCA, non-linear NCA, t-distributed NCA, t-distributed MCML, supervised UMAP, supervised PCA, Colored Maximum Variance Unfolding, supervised Isomap, Parametric Embedding, supervised Neighbor Retrieval Visualizer, and Multiple Relational Embedding. An analysis of variance using PCA demonstrates that a non-linear preprocessing by the CE transformation of the data captures more variance than PCA by dimension.
[ Hall J ]


Scope of Reproduciblity Gao et al. propose to leverage policies consisting of a series of data augmentations for preventing the possibility of reconstruction attacks on the training data of gradients. The goal of this study is to: (1) Verify the findings of the authors about the performance of the found policies and the correlation between the reconstruction metric and provided protection. (2) Explore if the defence generalizes to an attacker that has knowledge about the policy used. Methodology For the experiments conducted in this research, parts of the code from Gao et al, were refactored to allow for more clear and robust experimentation. Approximately a week of computation time is needed for our experiments on a 1080 Ti GPU. Results It was possible to verify the results from the original paper within a reasonable margin of error. However, the reproduced results show that the claimed protection does not generalize to an attacker that has knowledge over the augmentations used. Additionally, the results show that the optimal augmentations are often predictable since the policies found by the proposed search algorithm mostly consist of the augmentations that perform best individually. What was easy The design of the search algorithm allowed for easy …
[ Hall J ]
Spectral inference on multiple networks is a rapidly-developing subfield of graph statistics. Recent work has demonstrated that joint, or simultaneous, spectral embedding of multiple independent networks can deliver more accurate estimation than individual spectral decompositions of those same networks. Such inference procedures typically rely heavily on independence assumptions across the multiple network realizations, and even in this case, little attention has been paid to the induced network correlation that can be a consequence of such joint embeddings. In this paper, we present a generalized omnibus embedding methodology and we provide a detailed analysis of this embedding across both independent and correlated networks, the latter of which significantly extends the reach of such procedures, and we describe how this omnibus embedding can itself induce correlation. This leads us to distinguish betwee inherent correlation---that is, the correlation that arises naturally in multisample network data---and induced correlation, which is an artifice of the joint embedding methodology. We show that the generalized omnibus embedding procedure is flexible and robust, and we prove both consistency and a central limit theorem for the embedded points. We examine how induced and inherent correlation can impact inference for network time series data, and we provide network analogues of …

The following submission is a reproducibility report for 'Background-Aware Pooling and Noise-Aware Loss for Weakly-Supervised Semantic Segmentation' published in CVPR 2021 as part of the ML Reproducibility Challenge 2021. The paper’s central claim revolves around the newly introduced Background Aware Pooling method to generate high-quality pseudo labels using bounding boxes as supervision and Noise Aware Loss to train a segmentation network using those noisy labels. We started with the publicly available code-base provided by the authors and reproduced the results involving pseudo label generation. Further, we implemented Noise-Aware Loss and used it to train a semantic segmentation network, reproducing its claims. We performed many refactoring and upgrades on the author's code to include various procedures mentioned in the paper as well as reimplemented the code base in PyTorch Lightning for easier reproducibility. To formulate the report, extensive experimentation on the author's code has been conducted to verify all the claims made by the author described in detail below. We also performed additional experiments to gauge the extent of improvement brought upon by the method over the state-of-the-art methods.
[ Hall J ]

This work aims to reproduce Lang et al.'s StylEx which proposes a novel approach to explain how a classifier makes its decision. They claim that StylEx creates a post-hoc counterfactual explanation whose principal attributes correspond to properties that are intuitive to humans. The paper boasts a large range of real-world practicality. However, StylEx proves difficult to reproduce due to its time complexity and holes in the information provided. This paper tries to fill in these holes by: i) re-implementation of StylEx in a different framework, ii) creating a low resource training benchmark.
[ Hall J ]
[ Hall J ]
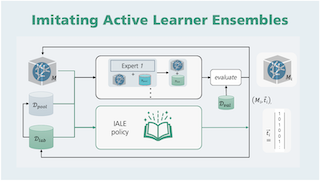
Active learning prioritizes the labeling of the most informative data samples. However, the performance of active learning heuristics depends on both the structure of the underlying model architecture and the data. We propose IALE, an imitation learning scheme that imitates the selection of the best-performing expert heuristic at each stage of the learning cycle in a batch-mode pool-based setting. We use Dagger to train a transferable policy on a dataset and later apply it to different datasets and deep classifier architectures. The policy reflects on the best choices from multiple expert heuristics given the current state of the active learning process, and learns to select samples in a complementary way that unifies the expert strategies. Our experiments on well-known image datasets show that we outperform state of the art imitation learners and heuristics.
The following paper is a reproducibility report for 'Social NCE: Contrastive Learning of Socially-aware Motion Representations' published in ICCV 2021 as part of the ML Reproducibility Challenge 2021. The original code was made available by the authors. We attempted to verify the results claimed by the authors and reimplemented their code in PyTorch Lightning.

Scope of Reproducibility In this work, we study the reproducibility of the paper Counterfactual Generative Networks (CGN) by Sauer and Geiger to verify their main claims, which state that (i) their proposed model can reliably generate high-quality counterfactual images by disentangling the shape, texture and background of the image into independent mechanisms, (ii) each independent mechanism has to be considered, and jointly optimizing all of them end-to-end is needed for high-quality images, and (iii) despite being synthetic, these counterfactual images can improve out-of-distribution performance of classifiers by making them invariant to spurious signals. Methodology The authors of the paper provide the implementation of CGN training in PyTorch. However, they did not provide code for all experiments. Consequently, we re-implemented the code for most experiments, and run each experiment on 1080 Ti GPUs. Our reproducibility study comes at a total computational cost of 112 GPU hours. Results We find that the main claims of the paper of (i) generating high-quality counterfactuals, (ii) utilizing appropriate inductive biases, and (iii) using them to instil invariance in classifiers, do largely hold. However, we found certain experiments that were not directly reproducible due to either inconsistency between the paper and code, or incomplete specification of …
[ Hall J ]

We conducted a reproducibility study of the paper 'Exacerbating Algorithmic Bias through Fairness Attacks'. According to the paper, current research on adversarial attacks is primarily focused on targeting model performance, which motivates the need for adversarial attacks on fairness. To that end, the authors propose two novel data poisoning adversarial attacks, the influence attack on fairness and the anchoring attack. We aim to verify the main claims of the paper, namely that: a) the proposed methods indeed affect a model's fairness and outperform existing attacks, b) the anchoring attack hardly affects performance, while impacting fairness, and c) the influence attack on fairness provides a controllable trade-off between performance and fairness degradation.
[ Hall J ]
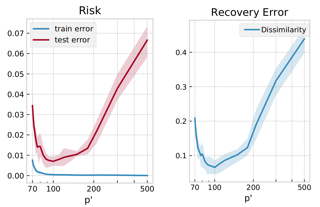
In over two decades of research, the field of dictionary learning has gathered a large collection of successful applications, and theoretical guarantees for model recovery are known only whenever optimization is carried out in the same model class as that of the underlying dictionary. This work characterizes the surprising phenomenon that dictionary recovery can be facilitated by searching over the space of larger over-realized models. This observation is general and independent of the specific dictionary learning algorithm used. We thoroughly demonstrate this observation in practice and provide an analysis of this phenomenon by tying recovery measures to generalization bounds. In particular, we show that model recovery can be upper-bounded by the empirical risk, a model-dependent quantity and the generalization gap, reflecting our empirical findings. We further show that an efficient and provably correct distillation approach can be employed to recover the correct atoms from the over-realized model. As a result, our meta-algorithm provides dictionary estimates with consistently better recovery of the ground-truth model.