[ Hall J ]

We introduce Breaking Bad, a large-scale dataset of fractured objects. Our dataset consists of over one million fractured objects simulated from ten thousand base models. The fracture simulation is powered by a recent physically based algorithm that efficiently generates a variety of fracture modes of an object. Existing shape assembly datasets decompose objects according to semantically meaningful parts, effectively modeling the construction process. In contrast, Breaking Bad models the destruction process of how a geometric object naturally breaks into fragments. Our dataset serves as a benchmark that enables the study of fractured object reassembly and presents new challenges for geometric shape understanding. We analyze our dataset with several geometry measurements and benchmark three state-of-the-art shape assembly deep learning methods under various settings. Extensive experimental results demonstrate the difficulty of our dataset, calling on future research in model designs specifically for the geometric shape assembly task. We host our dataset at https://breaking-bad-dataset.github.io/.
[ Hall J ]

[ Hall J ]
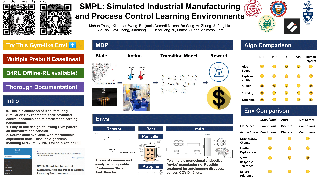
Traditional biological and pharmaceutical manufacturing plants are controlled by human workers or pre-defined thresholds. Modernized factories have advanced process control algorithms such as model predictive control (MPC). However, there is little exploration of applying deep reinforcement learning to control manufacturing plants. One of the reasons is the lack of high fidelity simulations and standard APIs for benchmarking. To bridge this gap, we develop an easy-to-use library that includes five high-fidelity simulation environments: BeerFMTEnv, ReactorEnv, AtropineEnv, PenSimEnv and mAbEnv, which cover a wide range of manufacturing processes. We build these environments on published dynamics models. Furthermore, we benchmark online and offline, model-based and model-free reinforcement learning algorithms for comparisons of follow-up research.
[ Hall J ]
Finance is a particularly challenging playground for deep reinforcement learning. However, establishing high-quality market environments and benchmarks for financial reinforcement learning is challenging due to three major factors, namely, low signal-to-noise ratio of financial data, survivorship bias of historical data, and backtesting overfitting. In this paper, we present an openly accessible FinRL-Meta library that has been actively maintained by the AI4Finance community. First, following a DataOps paradigm, we will provide hundreds of market environments through an automatic data curation pipeline that processes dynamic datasets from real-world markets into gym-style market environments. Second, we reproduce popular papers as stepping stones for users to design new trading strategies. We also deploy the library on cloud platforms so that users can visualize their own results and assess the relative performance via community-wise competitions. Third, FinRL-Meta provides tens of Jupyter/Python demos organized into a curriculum and a documentation website to serve the rapidly growing community. FinRL-Meta is available at: \url{https://github.com/AI4Finance-Foundation/FinRL-Meta}
[ Hall J ]

We present Myriad, a testbed written in JAX which enables machine learning researchers to benchmark imitation learning and reinforcement learning algorithms against trajectory optimization-based methods in real-world environments. Myriad contains 17 optimal control problems presented in continuous time which span medicine, ecology, epidemiology, and engineering. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. The repository also provides machine learning practitioners access to trajectory optimization techniques, not only for standalone use, but also for integration within a typical automatic differentiation workflow. Indeed, the combination of classical control theory and deep learning in a fully GPU-compatible package unlocks potential for new algorithms to arise. We present one such novel approach for use in dynamics learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with unknown environment dynamics. All environments, optimizers and tools are available in the software package at \url{https://github.com/nikihowe/myriad}.
[ Hall J ]
Flying at speed through complex environments is a challenging task that has been performed successfully by insects since the Carboniferous, but which remains a challenge for robotic and autonomous systems. Insects navigate the world using optical flow sensed by their compound eyes, which they process using a deep neural network weighing just a few milligrams. Deploying an insect-inspired network architecture in computer vision could therefore enable more efficient and effective ways of estimating structure and self-motion using optical flow. Training a bio-informed deep network to implement these tasks requires biologically relevant training, test, and validation data. To this end, we introduce FlyView, a novel bio-informed truth dataset for visual navigation. This simulated dataset is rendered using open source 3D scenes in which the observer's position is known at every frame, and is accompanied by truth data on depth, self-motion, and motion flow. This dataset comprising 42,475 frames has several key features that are missing from existing optical flow datasets, including: (i) panoramic cameras with a monocular and binocular field of view matched to that of a fly's compound eyes; (ii) dynamically meaningful self-motion modelled on motion primitives, or the 3D trajectories of drones and flies; and (iii) complex natural and …
[ Hall J ]
Machine learning on blockchain graphs is an emerging field with many applications such as ransomware payment tracking, price manipulation analysis, and money laundering detection. However, analyzing blockchain data requires domain expertise and computational resources, which pose a significant barrier and hinder advancement in this field. We introduce Chartalist, the first comprehensive platform to methodically access and use machine learning across a large selection of blockchains to address this challenge. Chartalist contains ML-ready datasets from unspent transaction output (UTXO) (e.g., Bitcoin) and account-based blockchains (e.g., Ethereum). We envision that Chartalist can facilitate data modeling, analysis, and representation of blockchain data and attract a wider community of scientists to analyze blockchains. Chartalist is an open-science initiative at https://github.com/cakcora/Chartalist.
[ Hall J ]
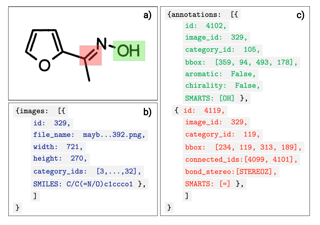
Optical Chemical Structure Recognition (OCSR) deals with the translation from chemical images to molecular structures, this being the main way chemical compounds are depicted in scientific documents. Traditionally, rule-based methods have followed a framework based on the detection of chemical entities, such as atoms and bonds, followed by a compound structure reconstruction step. Recently, neural architectures analog to image captioning have been explored to solve this task, yet they still show to be data inefficient, using millions of examples just to show performances comparable with traditional methods. Looking to motivate and benchmark new approaches based on atomic-level entities detection and graph reconstruction, we present CEDe, a unique collection of chemical entity bounding boxes manually curated by experts for scientific literature datasets. These annotations combine to more than 700,000 chemical entity bounding boxes with the necessary information for structure reconstruction. Also, a large synthetic dataset containing one million molecular images and annotations is released in order to explore transfer-learning techniques that could help these architectures perform better under low-data regimes. Benchmarks show that detection-reconstruction based models can achieve performances on par with or better than image captioning-like models, even with 100x fewer training examples.
[ Hall J ]
To improve the sustainability and resilience of modern food systems, designing improved crop management strategies is crucial. The increasing abundance of data on agricultural systems suggests that future strategies could benefit from adapting to environmental conditions, but how to design these adaptive policies poses a new frontier. A natural technique for learning policies in these kinds of sequential decision-making problems is reinforcement learning (RL). To obtain the large number of samples required to learn effective RL policies, existing work has used mechanistic crop growth models (CGMs) as simulators. These solutions focus on single-year, single-crop simulations for learning strategies for a single agricultural management practice. However, to learn sustainable long-term policies we must be able to train in multi-year environments, with multiple crops, and consider a wider array of management techniques. We introduce CYCLESGYM, an RL environment based on the multi-year, multi-crop CGM Cycles. CYCLESGYM allows for long-term planning in agroecosystems, provides modular state space and reward constructors and weather generators, and allows for complex actions. For RL researchers, this is a novel benchmark to investigate issues arising in real-world applications. For agronomists, we demonstrate the potential of RL as a powerful optimization tool for agricultural systems management in multi-year case …
[ Hall J ]

This paper introduces ActionSense, a multimodal dataset and recording framework with an emphasis on wearable sensing in a kitchen environment. It provides rich, synchronized data streams along with ground truth data to facilitate learning pipelines that could extract insights about how humans interact with the physical world during activities of daily living, and help lead to more capable and collaborative robot assistants. The wearable sensing suite captures motion, force, and attention information; it includes eye tracking with a first-person camera, forearm muscle activity sensors, a body-tracking system using 17 inertial sensors, finger-tracking gloves, and custom tactile sensors on the hands that use a matrix of conductive threads. This is coupled with activity labels and with externally-captured data from multiple RGB cameras, a depth camera, and microphones. The specific tasks recorded in ActionSense are designed to highlight lower-level physical skills and higher-level scene reasoning or action planning. They include simple object manipulations (e.g., stacking plates), dexterous actions (e.g., peeling or cutting vegetables), and complex action sequences (e.g., setting a table or loading a dishwasher). The resulting dataset and underlying experiment framework are available at https://action-sense.csail.mit.edu. Preliminary networks and analyses explore modality subsets and cross-modal correlations. ActionSense aims to support applications including …
[ Hall J ]
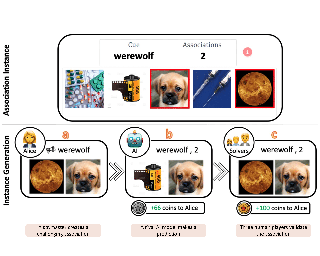
While vision-and-language models perform well on tasks such as visual question answering, they struggle when it comes to basic human commonsense reasoning skills. In this work, we introduce WinoGAViL: an online game of vision-and-language associations (e.g., between werewolves and a full moon), used as a dynamic evaluation benchmark. Inspired by the popular card game Codenames, a spymaster gives a textual cue related to several visual candidates, and another player tries to identify them. Human players are rewarded for creating associations that are challenging for a rival AI model but still solvable by other human players. We use the game to collect 3.5K instances, finding that they are intuitive for humans (>90% Jaccard index) but challenging for state-of-the-art AI models, where the best model (ViLT) achieves a score of 52%, succeeding mostly where the cue is visually salient. Our analysis as well as the feedback we collect from players indicate that the collected associations require diverse reasoning skills, including general knowledge, common sense, abstraction, and more. We release the dataset, the code and the interactive game, allowing future data collection that can be used to develop models with better association abilities.
[ Hall J ]
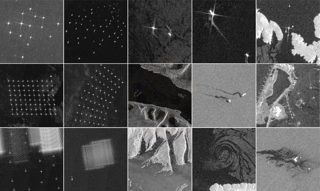
Unsustainable fishing practices worldwide pose a major threat to marine resources and ecosystems. Identifying vessels that do not show up in conventional monitoring systems---known as ``dark vessels''---is key to managing and securing the health of marine environments. With the rise of satellite-based synthetic aperture radar (SAR) imaging and modern machine learning (ML), it is now possible to automate detection of dark vessels day or night, under all-weather conditions. SAR images, however, require a domain-specific treatment and are not widely accessible to the ML community. Maritime objects (vessels and offshore infrastructure) are relatively small and sparse, challenging traditional computer vision approaches. We present the largest labeled dataset for training ML models to detect and characterize vessels and ocean structures in SAR imagery. xView3-SAR consists of nearly 1,000 analysis-ready SAR images from the Sentinel-1 mission that are, on average, 29,400-by-24,400 pixels each. The images are annotated using a combination of automated and manual analysis. Co-located bathymetry and wind state rasters accompany every SAR image. We also provide an overview of the xView3 Computer Vision Challenge, an international competition using xView3-SAR for ship detection and characterization at large scale. We release the data (\href{https://iuu.xview.us/}{https://iuu.xview.us/}) and code (\href{https://github.com/DIUx-xView}{https://github.com/DIUx-xView}) to support ongoing development and evaluation …
[ Hall J ]
Evaluating new techniques on realistic datasets plays a crucial role in the development of ML research and its broader adoption by practitioners. In recent years, there has been a significant increase of publicly available unstructured data resources for computer vision and NLP tasks. However, tabular data — which is prevalent in many high-stakes domains — has been lagging behind. To bridge this gap, we present Bank Account Fraud (BAF), the first publicly available 1 privacy-preserving, large-scale, realistic suite of tabular datasets. The suite was generated by applying state-of-the-art tabular data generation techniques on an anonymized,real-world bank account opening fraud detection dataset. This setting carries a set of challenges that are commonplace in real-world applications, including temporal dynamics and significant class imbalance. Additionally, to allow practitioners to stress test both performance and fairness of ML methods, each dataset variant of BAF contains specific types of data bias. With this resource, we aim to provide the research community with a more realistic, complete, and robust test bed to evaluate novel and existing methods.
[ Hall J ]

Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/LargeScaleGCN_Benchmarking.
[ Hall J ]

Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.
[ Hall J ]
Most existing neural architecture search (NAS) benchmarks and algorithms prioritize well-studied tasks, e.g. image classification on CIFAR or ImageNet. This makes the performance of NAS approaches in more diverse areas poorly understood. In this paper, we present NAS-Bench-360, a benchmark suite to evaluate methods on domains beyond those traditionally studied in architecture search, and use it to address the following question: do state-of-the-art NAS methods perform well on diverse tasks? To construct the benchmark, we curate ten tasks spanning a diverse array of application domains, dataset sizes, problem dimensionalities, and learning objectives. Each task is carefully chosen to interoperate with modern CNN-based search methods while possibly being far-afield from its original development domain. To speed up and reduce the cost of NAS research, for two of the tasks we release the precomputed performance of 15,625 architectures comprising a standard CNN search space. Experimentally, we show the need for more robust NAS evaluation of the kind NAS-Bench-360 enables by showing that several modern NAS procedures perform inconsistently across the ten tasks, with many catastrophically poor results. We also demonstrate how NAS-Bench-360 and its associated precomputed results will enable future scientific discoveries by testing whether several recent hypotheses promoted in the NAS …
[ Hall J ]

Foundational Models (FMs) have demonstrated unprecedented capabilities including zero-shot learning, high fidelity data synthesis, and out of domain generalization. However, the parameter capacity of FMs is still limited, leading to poor out-of-the-box performance of FMs on many expert tasks (e.g. retrieval of car manuals technical illustrations from language queries), data for which is either unseen or belonging to a long-tail part of the data distribution of the huge datasets used for FM pre-training. This underlines the necessity to explicitly evaluate and finetune FMs on such expert tasks, arguably ones that appear the most in practical real-world applications. In this paper, we propose a first of its kind FETA benchmark built around the task of teaching FMs to understand technical documentation, via learning to match their graphical illustrations to corresponding language descriptions. Our FETA benchmark focuses on text-to-image and image-to-text retrieval in public car manuals and sales catalogue brochures. FETA is equipped with a procedure for completely automatic annotation extraction (code would be released upon acceptance), allowing easy extension of FETA to more documentation types and application domains in the future. Our automatic annotation leads to an automated performance metric shown to be consistent with metrics computed on human-curated annotations (also …[ Hall J ]
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple …
[ Hall J ]

The ability of a document classifier to handle inputs that are drawn from a distribution different from the training distribution is crucial for robust deployment and generalizability. The RVL-CDIP corpus is the de facto standard benchmark for document classification, yet to our knowledge all studies that use this corpus do not include evaluation on out-of-distribution documents. In this paper, we curate and release a new out-of-distribution benchmark for evaluating out-of-distribution performance for document classifiers. Our new out-of-distribution benchmark consists of two types of documents: those that are not part of any of the 16 in-domain RVL-CDIP categories (RVL-CDIP-O), and those that are one of the 16 in-domain categories yet are drawn from a distribution different from that of the original RVL-CDIP dataset (RVL-CDIP-N). While prior work on document classification for in-domain RVL-CDIP documents reports high accuracy scores, we find that these models exhibit accuracy drops of between roughly 15-30% on our new out-of-domain RVL-CDIP-N benchmark, and further struggle to distinguish between in-domain RVL-CDIP-N and out-of-domain RVL-CDIP-O inputs. Our new benchmark provides researchers with a valuable new resource for analyzing out-of-distribution performance on document classifiers.
[ Hall J ]
Echocardiography is one of the most commonly used diagnostic imaging modalities in cardiology. Application of deep learning models to echocardiograms can enable automated identification of cardiac structures, estimation of cardiac function, and prediction of clinical outcomes. However, a major hindrance to realizing the full potential of deep learning is the lack of large-scale, fully curated and annotated data sets required for supervised training. High-quality pre-trained representations that can transfer useful visual features of echocardiograms to downstream tasks can help adapt deep learning models to new setups using fewer examples. In this paper, we design a suite of benchmarks that can be used to pre-train and evaluate echocardiographic representations with respect to various clinically-relevant tasks using publicly accessible data sets. In addition, we develop a unified evaluation protocol---which we call the echocardiographic task adaptation benchmark (ETAB)---that measures how well a visual representation of echocardiograms generalizes to common downstream tasks of interest. We use our benchmarking framework to evaluate state-of-the-art vision modeling pipelines. We envision that our standardized, publicly accessible benchmarks would encourage future research and expedite progress in applying deep learning to high-impact problems in cardiovascular medicine.
[ Hall J ]
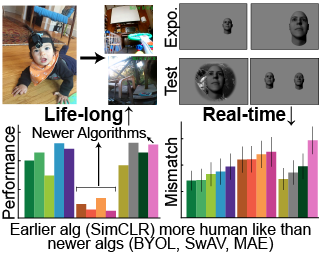
Humans learn from visual inputs at multiple timescales, both rapidly and flexibly acquiring visual knowledge over short periods, and robustly accumulating online learning progress over longer periods. Modeling these powerful learning capabilities is an important problem for computational visual cognitive science, and models that could replicate them would be of substantial utility in real-world computer vision settings. In this work, we establish benchmarks for both real-time and life-long continual visual learning. Our real-time learning benchmark measures a model's ability to match the rapid visual behavior changes of real humans over the course of minutes and hours, given a stream of visual inputs. Our life-long learning benchmark evaluates the performance of models in a purely online learning curriculum obtained directly from child visual experience over the course of years of development. We evaluate a spectrum of recent deep self-supervised visual learning algorithms on both benchmarks, finding that none of them perfectly match human performance, though some algorithms perform substantially better than others. Interestingly, algorithms embodying recent trends in self-supervised learning -- including BYOL, SwAV and MAE -- are substantially worse on our benchmarks than an earlier generation of self-supervised algorithms such as SimCLR and MoCo-v2. We present analysis indicating that the …
[ Hall J ]
Personalized Federated Learning (pFL), which utilizes and deploys distinct local models, has gained increasing attention in recent years due to its success in handling the statistical heterogeneity of FL clients. However, standardized evaluation and systematical analysis of diverse pFL methods remain a challenge. Firstly, the highly varied datasets, FL simulation settings and pFL implementations prevent easy and fair comparisons of pFL methods. Secondly, the current pFL literature diverges in the adopted evaluation and ablation protocols. Finally, the effectiveness and robustness of pFL methods are under-explored in various practical scenarios, such as the generalization to new clients and the participation of resource-limited clients. To tackle these challenges, we propose the first comprehensive pFL benchmark, pFL-Bench, for facilitating rapid, reproducible, standardized and thorough pFL evaluation. The proposed benchmark contains more than 10 dataset variants in various application domains with a unified data partition and realistic heterogeneous settings; a modularized and easy-to-extend pFL codebase with more than 20 competitive pFL method implementations; and systematic evaluations under containerized environments in terms of generalization, fairness, system overhead, and convergence. We highlight the benefits and potential of state-of-the-art pFL methods and hope pFL-Bench enables further pFL research and broad applications that would otherwise be difficult owing …
[ Hall J ]
[ Hall J ]

Keyphrases are an important tool for efficiently dealing with the ever-increasing amount of information present on the internet. While there are many recent papers on English keyphrase generation, keyphrase generation for other languages remains vastly understudied, mostly due to the absence of datasets. To address this, we present a novel dataset called Papyrus, composed of 16427 pairs of abstracts and keyphrases. We release four versions of this dataset, corresponding to different subtasks. Papyrus-e considers only English keyphrases, Papyrus-f considers French keyphrases, Papyrus-m considers keyphrase generation in any language (mostly French and English), and Papyrus-a considers keyphrase generation in several languages. We train a state-of-the-art model on all four tasks and show that they lead to better results for non-English languages, with an average improvement of 14.2\% on keyphrase extraction and 2.0\% on generation. We also show an improvement of 0.4\% on extraction and 0.7\% on generation over English state-of-the-art results by concatenating Papyrus-e with the Kp20K training set.
[ Hall J ]
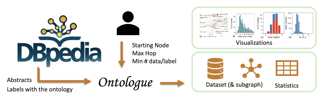
We describe a customizable benchmark for hierarchical and ontological multi-label classification, a task where labels are equipped with a graph structure and data items can be assigned multiple labels. We find that current benchmarks do not adequately represent the problem space, casting doubt on the generalizability of current results. We consider three dimensions of the problem space: context (availability of rich features on the data and labels), distribution of labels over data, and graph structure. For context, the lack of complex features on the labels (and in some cases, the data) artificially prevent the use of modern representation learning techniques as an appropriate baseline. For distribution, we find the long tail of labels over data constitute a few-shot learning problem that artificially confounds the results: for most common benchmarks, over 40% of the labels have fewer than 5 data points in the training set. For structure, we find that the correlation between performance and the height of the tree can explain some of the variation in performance, informing practical utility. In this paper, we demonstrate how the lack of diversity in benchmarks can confound performance analysis, then present a declarative query system called Ontologue for generating custom benchmarks with specific …
[ Hall J ]
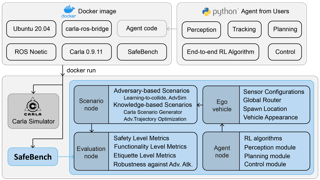
As shown by recent studies, machine intelligence-enabled systems are vulnerable to test cases resulting from either adversarial manipulation or natural distribution shifts. This has raised great concerns about deploying machine learning algorithms for real-world applications, especially in safety-critical domains such as autonomous driving (AD). On the other hand, traditional AD testing on naturalistic scenarios requires hundreds of millions of driving miles due to the high dimensionality and rareness of the safety-critical scenarios in the real world. As a result, several approaches for autonomous driving evaluation have been explored, which are usually, however, based on different simulation platforms, types of safety-critical scenarios, scenario generation algorithms, and driving route variations. Thus, despite a large amount of effort in autonomous driving testing, it is still challenging to compare and understand the effectiveness and efficiency of different testing scenario generation algorithms and testing mechanisms under similar conditions. In this paper, we aim to provide the first unified platform SafeBench to integrate different types of safety-critical testing scenarios, scenario generation algorithms, and other variations such as driving routes and environments. In particular, we consider 8 safety-critical testing scenarios following National Highway Traffic Safety Administration (NHTSA) and develop 4 scenario generation algorithms considering 10 variations for …
[ Hall J ]

There has been significant progress in developing reinforcement learning (RL) training systems. Past works such as IMPALA, Apex, Seed RL, Sample Factory, and others, aim to improve the system's overall throughput. In this paper, we aim to address a common bottleneck in the RL training system, i.e., parallel environment execution, which is often the slowest part of the whole system but receives little attention. With a curated design for paralleling RL environments, we have improved the RL environment simulation speed across different hardware setups, ranging from a laptop and a modest workstation, to a high-end machine such as NVIDIA DGX-A100. On a high-end machine, EnvPool achieves one million frames per second for the environment execution on Atari environments and three million frames per second on MuJoCo environments. When running EnvPool on a laptop, the speed is 2.8x that of the Python subprocess. Moreover, great compatibility with existing RL training libraries has been demonstrated in the open-sourced community, including CleanRL, rl_games, DeepMind Acme, etc. Finally, EnvPool allows researchers to iterate their ideas at a much faster pace and has great potential to become the de facto RL environment execution engine. Example runs show that it only takes five minutes to train …
[ Hall J ]

Hand, the bearer of human productivity and intelligence, is receiving much attention due to the recent fever of digital twins. Among different hand morphable models, MANO has been widely used in vision and graphics community. However, MANO disregards textures and accessories, which largely limits its power to synthesize photorealistic hand data. In this paper, we extend MANO with Diverse Accessories and Rich Textures, namely DART. DART is composed of 50 daily 3D accessories which varies in appearance and shape, and 325 hand-crafted 2D texture maps covers different kinds of blemishes or make-ups. Unity GUI is also provided to generate synthetic hand data with user-defined settings, e.g., pose, camera, background, lighting, textures, and accessories. Finally, we release DARTset, which contains large-scale (800K), high-fidelity synthetic hand images, paired with perfect-aligned 3D labels. Experiments demonstrate its superiority in diversity. As a complement to existing hand datasets, DARTset boosts the generalization in both hand pose estimation and mesh recovery tasks. Raw ingredients (textures, accessories), Unity GUI, source code and DARTset are publicly available at dart2022.github.io.
[ Hall J ]
Automatic action identification from video and kinematic data is an important machine learning problem with applications ranging from robotics to smart health. Most existing works focus on identifying coarse actions such as running, climbing, or cutting vegetables, which have relatively long durations and a complex series of motions. This is an important limitation for applications that require identification of more elemental motions at high temporal resolution. For example, in the rehabilitation of arm impairment after stroke, quantifying the training dose (number of repetitions) requires differentiating motions with sub-second durations. Our goal is to bridge this gap. To this end, we introduce a large-scale, multimodal dataset, StrokeRehab, as a new action-recognition benchmark that includes elemental short-duration actions labeled at a high temporal resolution. StrokeRehab consists of a high-quality inertial measurement unit sensor and video data of 51 stroke-impaired patients and 20 healthy subjects performing activities of daily living like feeding, brushing teeth, etc. Because it contains data from both healthy and impaired individuals, StrokeRehab can be used to study the influence of distribution shift in action-recognition tasks. When evaluated on StrokeRehab, current state-of-the-art models for action segmentation produce noisy predictions, which reduces their accuracy in identifying the corresponding sequence of actions. …
[ Hall J ]

It is well-known in the video understanding community that human action recognition models suffer from background bias, i.e., over-relying on scene cues in making their predictions. However, it is difficult to quantify this effect using existing evaluation frameworks. We introduce the Human-centric Analysis Toolkit (HAT), which enables evaluation of learned background bias without the need for new manual video annotation. It does so by automatically generating synthetically manipulated videos and leveraging the recent advances in image segmentation and video inpainting. Using HAT we perform an extensive analysis of 74 action recognition models trained on the Kinetics dataset. We confirm that all these models focus more on the scene background than on the human motion; further, we demonstrate that certain model design decisions (such as training with fewer frames per video or using dense as opposed to uniform temporal sampling) appear to worsen the background bias. We open-source HAT to enable the community to design more robust and generalizable human action recognition models.
[ Hall J ]

With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC, https://clearinghouse.net), which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further summarization research and to facilitate the …
[ Hall J ]

The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become a de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark\ (klej is the word for glue in Polish) has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world.In this paper, we introduce LEPISZCZE (lepiszcze is the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark.We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 …
[ Hall J ]
Recently, graph neural networks have been gaining a lot of attention to simulate dynamical systems due to their inductive nature leading to zero-shot generalizability. Similarly, physics-informed inductive biases in deep-learning frameworks have been shown to give superior performance in learning the dynamics of physical systems. There is a growing volume of literature that attempts to combine these two approaches. Here, we evaluate the performance of thirteen different graph neural networks, namely, Hamiltonian and Lagrangian graph neural networks, graph neural ODE, and their variants with explicit constraints and different architectures. We briefly explain the theoretical formulation highlighting the similarities and differences in the inductive biases and graph architecture of these systems. Then, we evaluate them on spring, pendulum, and gravitational and 3D deformable solid systems to compare the performance in terms of rollout error, conserved quantities such as energy and momentum, and generalizability to unseen system sizes. Our study demonstrates that GNNs with additional inductive biases, such as explicit constraints and decoupling of kinetic and potential energies, exhibit significantly enhanced performance. Further, all the physics-informed GNNs exhibit zero-shot generalizability to system sizes an order of magnitude larger than the training system, thus providing a promising route to simulate large-scale realistic systems.
[ Hall J ]
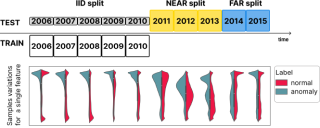
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning (ML), leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, built over Kyoto-2006+, a traffic dataset for network intrusion detection. This type of data meets the premise of shifting the input distribution: it covers a large time span (10 years), with naturally occurring changes over time (e.g. users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years. Next, we propose AnoShift, a protocol splitting the data in IID, NEAR, and FAR testing splits. We validate the performance degradation over time with diverse models, ranging from classical approaches to deep learning. Finally, we show that by acknowledging the distribution shift problem and properly addressing it, the performance can be improved compared to the classical …
[ Hall J ]
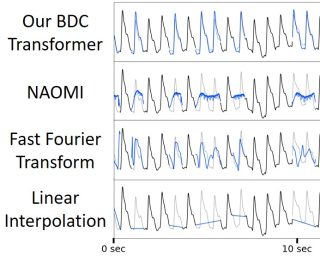
The promise of Mobile Health (mHealth) is the ability to use wearable sensors to monitor participant physiology at high frequencies during daily life to enable temporally-precise health interventions. However, a major challenge is frequent missing data. Despite a rich imputation literature, existing techniques are ineffective for the pulsative signals which comprise many mHealth applications, and a lack of available datasets has stymied progress. We address this gap with PulseImpute, the first large-scale pulsative signal imputation challenge which includes realistic mHealth missingness models, an extensive set of baselines, and clinically-relevant downstream tasks. Our baseline models include a novel transformer-based architecture designed to exploit the structure of pulsative signals. We hope that PulseImpute will enable the ML community to tackle this important and challenging task.
[ Hall J ]
As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
[ Hall J ]
Universal self-supervised (SSL) algorithms hold enormous promise for making machine learning accessible to high-impact domains such as protein biology, manufacturing, and genomics. We present DABS 2.0: a set of improved datasets and algorithms for advancing research on universal SSL. We extend the recently-introduced DABS benchmark with the addition of five real-world science and engineering domains: protein biology, bacterial genomics, multispectral satellite imagery, semiconductor wafers, and particle physics, bringing the total number of domains in the benchmark to twelve. We also propose a new universal SSL algorithm, Capri, and a generalized version of masked autoencoding, and apply both on all twelve domains---the most wide-ranging exploration of SSL yet. We find that multiple algorithms show gains across domains, outperforming previous baselines. In addition, we demonstrate the usefulness of DABS for scientific study of SSL by investigating the optimal corruption rate for each algorithm, showing that the best setting varies based on the domain. Code will be released at http://github.com/alextamkin/dabs}{http://github.com/alextamkin/dabs
[ Hall J ]
We introduce HandMeThat, a benchmark for a holistic evaluation of instruction understanding and following in physical and social environments. While previous datasets primarily focused on language grounding and planning, HandMeThat considers the resolution of human instructions with ambiguities based on the physical (object states and relations) and social (human actions and goals) information. HandMeThat contains 10,000 episodes of human-robot interactions. In each episode, the robot first observes a trajectory of human actions towards her internal goal. Next, the robot receives a human instruction and should take actions to accomplish the subgoal set through the instruction. In this paper, we present a textual interface for our benchmark, where the robot interacts with a virtual environment through textual commands. We evaluate several baseline models on HandMeThat, and show that both offline and online reinforcement learning algorithms perform poorly on HandMeThat, suggesting significant room for future work on physical and social human-robot communications and interactions.
[ Hall J ]
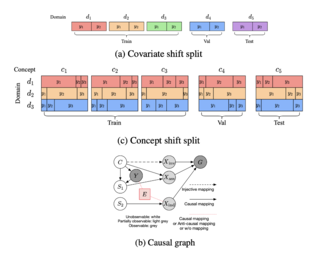
Out-of-distribution (OOD) learning deals with scenarios in which training and test data follow different distributions. Although general OOD problems have been intensively studied in machine learning, graph OOD is only an emerging area of research. Currently, there lacks a systematic benchmark tailored to graph OOD method evaluation. In this work, we aim at developing an OOD benchmark, known as GOOD, for graphs specifically. We explicitly make distinctions between covariate and concept shifts and design data splits that accurately reflect different shifts. We consider both graph and node prediction tasks as there are key differences in designing shifts. Overall, GOOD contains 11 datasets with 17 domain selections. When combined with covariate, concept, and no shifts, we obtain 51 different splits. We provide performance results on 10 commonly used baseline methods with 10 random runs. This results in 510 dataset-model combinations in total. Our results show significant performance gaps between in-distribution and OOD settings. Our results also shed light on different performance trends between covariate and concept shifts by different methods. Our GOOD benchmark is a growing project and expects to expand in both quantity and variety of resources as the area develops. The GOOD benchmark can be accessed via https://github.com/divelab/GOOD/.
[ Hall J ]

Recent research has demonstrated the capability of behavior signals captured by smartphones and wearables for longitudinal behavior modeling. However, there is a lack of a comprehensive public dataset that serves as an open testbed for fair comparison among algorithms. Moreover, prior studies mainly evaluate algorithms using data from a single population within a short period, without measuring the cross-dataset generalizability of these algorithms. We present the first multi-year passive sensing datasets, containing over 700 user-years and 497 unique users’ data collected from mobile and wearable sensors, together with a wide range of well-being metrics. Our datasets can support multiple cross-dataset evaluations of behavior modeling algorithms’ generalizability across different users and years. As a starting point, we provide the benchmark results of 18 algorithms on the task of depression detection. Our results indicate that both prior depression detection algorithms and domain generalization techniques show potential but need further research to achieve adequate cross-dataset generalizability. We envision our multi-year datasets can support the ML community in developing generalizable longitudinal behavior modeling algorithms.
[ Hall J ]
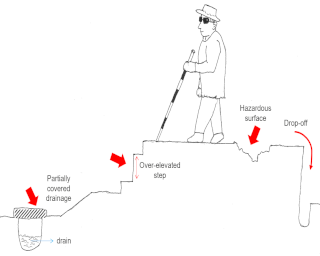
According to World Health Organization, there is an estimated 2.2 billion people with a near or distance vision impairment worldwide. Difficulty in self-navigation is one of the greatest challenges to independence for the blind and low vision (BLV) people. Through consultations with several BLV service providers, we realized that negotiating surface discontinuities is one of the very prominent challenges when navigating an outdoor environment within the urban. Surface discontinuities are commonly formed by rises and drop-offs along a pathway. They could be a threat to balancing during a walk and perceiving such a threat is highly challenging to the BLVs. In this paper, we introduce SurDis, a novel dataset of depth maps and stereo images that exemplifies the issue of surface discontinuity in the urban areas of Klang Valley, Malaysia. We seek to address the limitation of existing datasets of such nature in these areas. Current mobility tools for the BLVs predominantly focus on furniture, indoor built environments, traffic signs, vehicles, humans and various types of objects' detection above the surface of a pathway. We emphasize a specific purpose for SurDis – to support the development of assistive wearable technology for the BLVs to negotiate surface discontinuity. We consulted BLV …
[ Hall J ]

Autonomous agents have made great strides in specialist domains like Atari games and Go. However, they typically learn tabula rasa in isolated environments with limited and manually conceived objectives, thus failing to generalize across a wide spectrum of tasks and capabilities. Inspired by how humans continually learn and adapt in the open world, we advocate a trinity of ingredients for building generalist agents: 1) an environment that supports a multitude of tasks and goals, 2) a large-scale database of multimodal knowledge, and 3) a flexible and scalable agent architecture. We introduce MineDojo, a new framework built on the popular Minecraft game that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base with Minecraft videos, tutorials, wiki pages, and forum discussions. Using MineDojo's data, we propose a novel agent learning algorithm that leverages large pre-trained video-language models as a learned reward function. Our agent is able to solve a variety of open-ended tasks specified in free-form language without any manually designed dense shaping reward. We open-source the simulation suite, knowledge bases, algorithm implementation, and pretrained models (https://minedojo.org) to promote research towards the goal of generally capable embodied agents.
[ Hall J ]
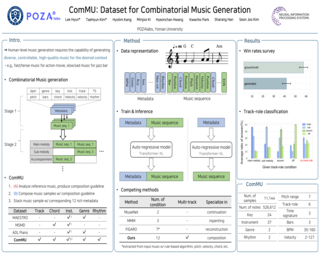
Commercial adoption of automatic music composition requires the capability of generating diverse and high-quality music suitable for the desired context (e.g., music for romantic movies, action games, restaurants, etc.). In this paper, we introduce combinatorial music generation, a new task to create varying background music based on given conditions. Combinatorial music generation creates short samples of music with rich musical metadata, and combines them to produce a complete music. In addition, we introduce ComMU, the first symbolic music dataset consisting of short music samples and their corresponding 12 musical metadata for combinatorial music generation. Notable properties of ComMU are that (1) dataset is manually constructed by professional composers with an objective guideline that induces regularity, and (2) it has 12 musical metadata that embraces composers' intentions. Our results show that we can generate diverse high-quality music only with metadata, and that our unique metadata such as track-role and extended chord quality improves the capacity of the automatic composition. We highly recommend watching our video before reading the paper (https://pozalabs.github.io/ComMU/).
[ Hall J ]

Artificial lights commonly leave strong lens flare artifacts on images captured at night. Nighttime flare not only affects the visual quality but also degrades the performance of vision algorithms. Existing flare removal methods mainly focus on removing daytime flares and fail in nighttime. Nighttime flare removal is challenging because of the unique luminance and spectrum of artificial lights and the diverse patterns and image degradation of the flares captured at night. The scarcity of nighttime flare removal datasets limits the research on this crucial task. In this paper, we introduce, Flare7K, the first nighttime flare removal dataset, which is generated based on the observation and statistics of real-world nighttime lens flares. It offers 5,000 scattering and 2,000 reflective flare images, consisting of 25 types of scattering flares and 10 types of reflective flares. The 7,000 flare patterns can be randomly added to flare-free images, forming the flare-corrupted and flare-free image pairs. With the paired data, we can train deep models to restore flare-corrupted images taken in the real world effectively. Apart from abundant flare patterns, we also provide rich annotations, including the labeling of light source, glare with shimmer, reflective flare, and streak, which are commonly absent from existing datasets. …
[ Hall J ]
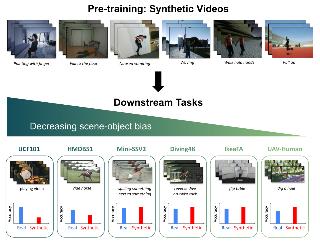
Action recognition has improved dramatically with massive-scale video datasets. Yet, these datasets are accompanied with issues related to curation cost, privacy, ethics, bias, and copyright. Compared to that, only minor efforts have been devoted toward exploring the potential of synthetic video data. In this work, as a stepping stone towards addressing these shortcomings, we study the transferability of video representations learned solely from synthetically-generated video clips, instead of real data. We propose SynAPT, a novel benchmark for action recognition based on a combination of existing synthetic datasets, in which a model is pre-trained on synthetic videos rendered by various graphics simulators, and then transferred to a set of downstream action recognition datasets, containing different categories than the synthetic data. We provide an extensive baseline analysis on SynAPT revealing that the simulation-to-real gap is minor for datasets with low object and scene bias, where models pre-trained with synthetic data even outperform their real data counterparts. We posit that the gap between real and synthetic action representations can be attributed to contextual bias and static objects related to the action, instead of the temporal dynamics of the action itself. The SynAPT benchmark is available at https://github.com/mintjohnkim/SynAPT.
[ Hall J ]

It is crucial that image datasets for computer vision are representative and contain accurate demographic information to ensure their robustness and fairness, especially for smaller subpopulations. To address this issue, we present Dollar Street - a supervised dataset that contains 38,479 images of everyday household items from homes around the world. This dataset was manually curated and fully labeled, including tags for objects (e.g. “toilet,” “toothbrush,” “stove”) and demographic data such as region, country and home monthly income. This dataset includes images from homes with no internet access and incomes as low as \$26.99 per month, visually capturing valuable socioeconomic diversity of traditionally under-represented populations. All images and data are licensed under CC-BY, permitting their use in academic and commercial work. Moreover, we show that this dataset can improve the performance of classification tasks for images of household items from lower income homes, addressing a critical need for datasets that combat bias.
[ Hall J ]

Progress in reinforcement learning (RL) research is often driven by the design of new, challenging environments---a costly undertaking requiring skills orthogonal to that of a typical machine learning researcher. The complexity of environment development has only increased with the rise of procedural-content generation (PCG) as the prevailing paradigm for producing varied environments capable of testing the robustness and generalization of RL agents. Moreover, existing environments often require complex build processes, making reproducing results difficult. To address these issues, we introduce GriddlyJS, a web-based Integrated Development Environment (IDE) based on the Griddly engine. GriddlyJS allows researchers to easily design and debug arbitrary, complex PCG grid-world environments, as well as visualize, evaluate, and record the performance of trained agent models. By connecting the RL workflow to the advanced functionality enabled by modern web standards, GriddlyJS allows publishing interactive agent-environment demos that reproduce experimental results directly to the web. To demonstrate the versatility of GriddlyJS, we use it to quickly develop a complex compositional puzzle-solving environment alongside arbitrary human-designed environment configurations and their solutions for use in a automatic curriculum learning and offline RL context. The GriddlyJS IDE is open source and freely available at https://griddly.ai.
[ Hall J ]
Despite the considerable progress in automatic abdominal multi-organ segmentation from CT/MRI scans in recent years, a comprehensive evaluation of the models' capabilities is hampered by the lack of a large-scale benchmark from diverse clinical scenarios. Constraint by the high cost of collecting and labeling 3D medical data, most of the deep learning models to date are driven by datasets with a limited number of organs of interest or samples, which still limits the power of modern deep models and makes it difficult to provide a fully comprehensive and fair estimate of various methods. To mitigate the limitations, we present AMOS, a large-scale, diverse, clinical dataset for abdominal organ segmentation. AMOS provides 500 CT and 100 MRI scans collected from multi-center, multi-vendor, multi-modality, multi-phase, multi-disease patients, each with voxel-level annotations of 15 abdominal organs, providing challenging examples and test-bed for studying robust segmentation algorithms under diverse targets and scenarios. We further benchmark several state-of-the-art medical segmentation models to evaluate the status of the existing methods on this new challenging dataset. We have made our datasets, benchmark servers, and baselines publicly available, and hope to inspire future research. Information can be found at https://amos22.grand-challenge.org.
[ Hall J ]
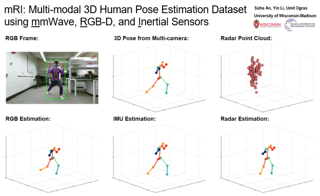
The ability to estimate 3D human body pose and movement, also known as human pose estimation (HPE), enables many applications for home-based health monitoring, such as remote rehabilitation training. Several possible solutions have emerged using sensors ranging from RGB cameras, depth sensors, millimeter-Wave (mmWave) radars, and wearable inertial sensors. Despite previous efforts on datasets and benchmarks for HPE, few dataset exploits multiple modalities and focuses on home-based health monitoring. To bridge the gap, we present mRI, a multi-modal 3D human pose estimation dataset with mmWave, RGB-D, and Inertial Sensors. Our dataset consists of over 160k synchronized frames from 20 subjects performing rehabilitation exercises and supports the benchmarks of HPE and action detection. We perform extensive experiments using our dataset and delineate the strength of each modality. We hope that the release of mRI can catalyze the research in pose estimation, multi-modal learning, and action understanding, and more importantly facilitate the applications of home-based health monitoring.
[ Hall J ]
Human-designed visual manuals are crucial components in shape assembly activities. They provide step-by-step guidance on how we should move and connect different parts in a convenient and physically-realizable way. While there has been an ongoing effort in building agents that perform assembly tasks, the information in human-design manuals has been largely overlooked. We identify that this is due to 1) a lack of realistic 3D assembly objects that have paired manuals and 2) the difficulty of extracting structured information from purely image-based manuals. Motivated by this observation, we present IKEA-Manual, a dataset consisting of 102 IKEA objects paired with assembly manuals. We provide fine-grained annotations on the IKEA objects and assembly manuals, including decomposed assembly parts, assembly plans, manual segmentation, and 2D-3D correspondence between 3D parts and visual manuals. We illustrate the broad application of our dataset on four tasks related to shape assembly: assembly plan generation, part segmentation, pose estimationand 3D part assembly.
[ Hall J ]
The past few years have seen the development of many benchmarks for Neural Architecture Search (NAS), fueling rapid progress in NAS research. However, recent work, which shows that good hyperparameter settings can be more important than using the best architecture, calls for a shift in focus towards Joint Architecture and Hyperparameter Search (JAHS). Therefore, we present JAHS-Bench-201, the first collection of surrogate benchmarks for JAHS, built to also facilitate research on multi-objective, cost-aware and (multi) multi-fidelity optimization algorithms. To the best of our knowledge, JAHS-Bench-201 is based on the most extensive dataset of neural network performance data in the public domain. It is composed of approximately 161 million data points and 20 performance metrics for three deep learning tasks, while featuring a 14-dimensional search and fidelity space that extends the popular NAS-Bench-201 space. With JAHS-Bench-201, we hope to democratize research on JAHS and lower the barrier to entry of an extremely compute intensive field, e.g., by reducing the compute time to run a JAHS algorithm from 5 days to only a few seconds.
[ Hall J ]

In stereo vision, self-similar or bland regions can make it difficult to match patches between two images. Active stereo-based methods mitigate this problem by projecting a pseudo-random pattern on the scene so that each patch of an image pair can be identified without ambiguity. However, the projected pattern significantly alters the appearance of the image. If this pattern acts as a form of adversarial noise, it could negatively impact the performance of deep learning-based methods, which are now the de-facto standard for dense stereo vision. In this paper, we propose the Active-Passive SimStereo dataset and a corresponding benchmark to evaluate the performance gap between passive and active stereo images for stereo matching algorithms. Using the proposed benchmark and an additional ablation study, we show that the feature extraction and matching modules of a selection of twenty selected deep learning-based stereo matching methods generalize to active stereo without a problem. However, the disparity refinement modules of three of the twenty architectures (ACVNet, CascadeStereo, and StereoNet) are negatively affected by the active stereo patterns due to their reliance on the appearance of the input images.
[ Hall J ]
Distribution shifts occur when the test distribution differs from the training distribution, and can considerably degrade performance of machine learning models deployed in the real world. While recent works have studied robustness to distribution shifts, distribution shifts arising from the passage of time have the additional structure of timestamp metadata. Real-world examples of such shifts are underexplored, and it is unclear whether existing models can leverage trends in past distribution shifts to reliably extrapolate into the future. To address this gap, we curate Wild-Time, a benchmark of 5 datasets that reflect temporal distribution shifts arising in a variety of real-world applications, including drug discovery, patient prognosis, and news classification. On these datasets, we systematically benchmark 13 approaches with various inductive biases. We evaluate methods in domain-generalization, continual learning, self-supervised learning, and ensemble learning, which leverage timestamps to extract the common structure of the distribution shifts. We extend several domain-generalization methods to the temporal distribution shift setting by treating windows of time as different domains. Finally, we propose two evaluation strategies to evaluate model performance under temporal distribution shifts---evaluation with a fixed time split (Eval-Fix) and evaluation with a data stream (Eval-Stream). Eval-Fix, our primary evaluation strategy, aims to provide a …
[ Hall J ]
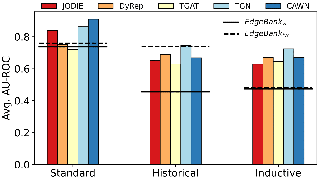
Despite the prevalence of recent success in learning from static graphs, learning from time-evolving graphs remains an open challenge. In this work, we design new, more stringent evaluation procedures for link prediction specific to dynamic graphs, which reflect real-world considerations, to better compare the strengths and weaknesses of methods. First, we create two visualization techniques to understand the reoccurring patterns of edges over time and show that many edges reoccur at later time steps. Based on this observation, we propose a pure memorization-based baseline called EdgeBank. EdgeBank achieves surprisingly strong performance across multiple settings which highlights that the negative edges used in the current evaluation are easy. To sample more challenging negative edges, we introduce two novel negative sampling strategies that improve robustness and better match real-world applications. Lastly, we introduce six new dynamic graph datasets from a diverse set of domains missing from current benchmarks, providing new challenges and opportunities for future research. Our code repository is accessible at https://github.com/fpour/DGB.git.
[ Hall J ]
Augmented Reality or AR filters on selfies have become very popular on social media platforms for a variety of applications, including marketing, entertainment and aesthetics. Given the wide adoption of AR face filters and the importance of faces in our social structures and relations, there is increased interest by the scientific community to analyze the impact of such filters from a psychological, artistic and sociological perspective. However, there are few quantitative analyses in this area mainly due to a lack of publicly available datasets of facial images with applied AR filters. The proprietary, close nature of most social media platforms does not allow users, scientists and practitioners to access the code and the details of the available AR face filters. Scraping faces from these platforms to collect data is ethically unacceptable and should, therefore, be avoided in research. In this paper, we present OpenFilter, a flexible framework to apply AR filters available in social media platforms on existing large collections of human faces. Moreover, we share FairBeauty and B-LFW, two beautified versions of the publicly available FairFace and LFW datasets and we outline insights derived from the analysis of these beautified datasets.
[ Hall J ]

Despite impressive successes, deep reinforcement learning (RL) systems still fall short of human performance on generalization to new tasks and environments that differ from their training. As a benchmark tailored for studying RL generalization, we introduce Avalon, a set of tasks in which embodied agents in highly diverse procedural 3D worlds must survive by navigating terrain, hunting or gathering food, and avoiding hazards. Avalon is unique among existing RL benchmarks in that the reward function, world dynamics, and action space are the same for every task, with tasks differentiated solely by altering the environment; its 20 tasks, ranging in complexity from eat and throw to hunt and navigate, each create worlds in which the agent must perform specific skills in order to survive. This setup enables investigations of generalization within tasks, between tasks, and to compositional tasks that require combining skills learned from previous tasks. Avalon includes a highly efficient simulator, a library of baselines, and a benchmark with scoring metrics evaluated against hundreds of hours of human performance, all of which are open-source and publicly available. We find that standard RL baselines make progress on most tasks but are still far from human performance, suggesting Avalon is challenging enough …
[ Hall J ]
Benefiting from language flexibility and compositionality, humans naturally intend to use language to command an embodied agent for complex tasks such as navigation and object manipulation. In this work, we aim to fill the blank of the last mile of embodied agents---object manipulation by following human guidance, e.g., “move the red mug next to the box while keeping it upright.” To this end, we introduce an Automatic Manipulation Solver (AMSolver) system and build a Vision-and-Language Manipulation benchmark (VLMbench) based on it, containing various language instructions on categorized robotic manipulation tasks. Specifically, modular rule-based task templates are created to automatically generate robot demonstrations with language instructions, consisting of diverse object shapes and appearances, action types, and motion constraints. We also develop a keypoint-based model 6D-CLIPort to deal with multi-view observations and language input and output a sequence of 6 degrees of freedom (DoF) actions. We hope the new simulator and benchmark will facilitate future research on language-guided robotic manipulation.
[ Hall J ]
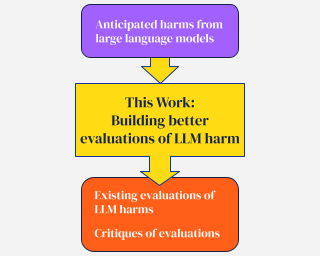
Large language models produce human-like text that drive a growing number of applications. However, recent literature and, increasingly, real world observations, have demonstrated that these models can generate language that is toxic, biased, untruthful or otherwise harmful. Though work to evaluate language model harms is under way, translating foresight about which harms may arise into rigorous benchmarks is not straightforward. To facilitate this translation, we outline six ways of characterizing harmful text which merit explicit consideration when designing new benchmarks. We then use these characteristics as a lens to identify trends and gaps in existing benchmarks. Finally, we apply them in a case study of the Perspective API, a toxicity classifier that is widely used in harm benchmarks. Our characteristics provide one piece of the bridge that translates between foresight and effective evaluation.
[ Hall J ]

Although online handwriting verification has made great progress recently, the verification performances are still far behind the real usage owing to the small scale of the datasets as well as the limited biometric mediums. Therefore, this paper proposes a new handwriting verification benchmark dataset named Multimodal Signature and Digit String (MSDS), which consists of two subsets: MSDS-ChS (Chinese Signatures) and MSDS-TDS (Token Digit Strings), contributed by 402 users, with 20 genuine samples and 20 skilled forgeries per user per subset. MSDS-ChS consists of handwritten Chinese signatures, which, to the best of our knowledge, is the largest publicly available Chinese signature dataset for handwriting verification, at least eight times larger than existing online datasets. Meanwhile, MSDS-TDS consists of handwritten Token Digit Strings, i.e, the actual phone numbers of users, which have not been explored yet. Extensive experiments with different baselines are respectively conducted for MSDS-ChS and MSDS-TDS. Surprisingly, verification performances of state-of-the-art methods on MSDS-TDS are generally better than those on MSDS-ChS, which indicates that the handwritten Token Digit String could be a more effective biometric than handwritten Chinese signature. This is a promising discovery that could inspire us to explore new biometric traits. The MSDS dataset is available at https://github.com/HCIILAB/MSDS.
[ Hall J ]

We present a new text-to-SQL dataset for electronic health records (EHRs). The utterances were collected from 222 hospital staff, including physicians, nurses, insurance review and health records teams, and more. To construct the QA dataset on structured EHR data, we conducted a poll at a university hospital and templatized the responses to create seed questions. Then, we manually linked them to two open-source EHR databases—MIMIC-III and eICU—and included them with various time expressions and held-out unanswerable questions in the dataset, which were all collected from the poll. Our dataset poses a unique set of challenges: the model needs to 1) generate SQL queries that reflect a wide range of needs in the hospital, including simple retrieval and complex operations such as calculating survival rate, 2) understand various time expressions to answer time-sensitive questions in healthcare, and 3) distinguish whether a given question is answerable or unanswerable based on the prediction confidence. We believe our dataset, EHRSQL, could serve as a practical benchmark to develop and assess QA models on structured EHR data and take one step further towards bridging the gap between text-to-SQL research and its real-life deployment in healthcare. EHRSQL is available at https://github.com/glee4810/EHRSQL.
[ Hall J ]

Analyzing the planet at scale with satellite imagery and machine learning is a dream that has been constantly hindered by the cost of difficult-to-access highly-representative high-resolution imagery. To remediate this, we introduce here the WorldStratified dataset. The largest and most varied such publicly available dataset, at Airbus SPOT 6/7 satellites' high resolution of up to 1.5 m/pixel, empowered by European Space Agency's Phi-Lab as part of the ESA-funded QueryPlanet project, we curate 10,000 sq km of unique locations to ensure stratified representation of all types of land-use across the world: from agriculture to ice caps, from forests to multiple urbanization densities. We also enrich those with locations typically under-represented in ML datasets: sites of humanitarian interest, illegal mining sites, and settlements of persons at risk. We temporally-match each high-resolution image with multiple low-resolution images from the freely accessible lower-resolution Sentinel-2 satellites at 10 m/pixel. We accompany this dataset with an open-source Python package to: rebuild or extend the WorldStrat dataset, train and infer baseline algorithms, and learn with abundant tutorials, all compatible with the popular EO-learn toolbox. We hereby hope to foster broad-spectrum applications of ML to satellite imagery, and possibly develop from free public low-resolution Sentinel2 imagery the same …
[ Hall J ]
Visual correspondence of 2D animation is the core of many applications and deserves careful study. Existing correspondence datasets for 2D cartoon suffer from simple frame composition and monotonic movements, making them insufficient to simulate real animations. In this work, we present a new 2D animation visual correspondence dataset, AnimeRun, by converting open source 3D movies to full scenes in 2D style, including simultaneous moving background and interactions of multiple subjects. Statistics show that our proposed dataset not only resembles real anime more in image composition, but also possesses richer and more complex motion patterns compared to existing datasets. With this dataset, we establish a comprehensive benchmark by evaluating several existing optical flow and segment matching methods, and analyze shortcomings of these methods on animation data. Data are available at https://lisiyao21.github.io/projects/AnimeRun.
[ Hall J ]

Molecular optimization is a fundamental goal in the chemical sciences and is of central interest to drug and material design. In recent years, significant progress has been made in solving challenging problems across various aspects of computational molecular optimizations, emphasizing high validity, diversity, and, most recently, synthesizability. Despite this progress, many papers report results on trivial or self-designed tasks, bringing additional challenges to directly assessing the performance of new methods. Moreover, the sample efficiency of the optimization---the number of molecules evaluated by the oracle---is rarely discussed, despite being an essential consideration for realistic discovery applications.To fill this gap, we have created an open-source benchmark for practical molecular optimization, PMO, to facilitate the transparent and reproducible evaluation of algorithmic advances in molecular optimization. This paper thoroughly investigates the performance of 25 molecular design algorithms on 23 single-objective (scalar) optimization tasks with a particular focus on sample efficiency. Our results show that most ``state-of-the-art'' methods fail to outperform their predecessors under a limited oracle budget allowing 10K queries and that no existing algorithm can efficiently solve certain molecular optimization problems in this setting. We analyze the influence of the optimization algorithm choices, molecular assembly strategies, and oracle landscapes on the optimization performance …
[ Hall J ]
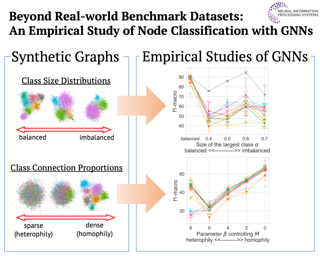
Graph Neural Networks (GNNs) have achieved great success on a node classification task. Despite the broad interest in developing and evaluating GNNs, they have been assessed with limited benchmark datasets. As a result, the existing evaluation of GNNs lacks fine-grained analysis from various characteristics of graphs. Motivated by this, we conduct extensive experiments with a synthetic graph generator that can generate graphs having controlled characteristics for fine-grained analysis. Our empirical studies clarify the strengths and weaknesses of GNNs from four major characteristics of real-world graphs with class labels of nodes, i.e., 1) class size distributions (balanced vs. imbalanced), 2) edge connection proportions between classes (homophilic vs. heterophilic), 3) attribute values (biased vs. random), and 4) graph sizes (small vs. large). In addition, to foster future research on GNNs, we publicly release our codebase that allows users to evaluate various GNNs with various graphs. We hope this work offers interesting insights for future research.
[ Hall J ]
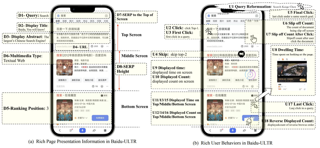
The unbiased learning to rank (ULTR) problem has been greatly advanced by recent deep learning techniques and well-designed debias algorithms. However, promising results on the existing benchmark datasets may not be extended to the practical scenario due to some limitations of existing datasets. First, their semantic feature extractions are outdated while state-of-the-art large-scale pre-trained language models like BERT cannot be utilized due to the lack of original text. Second, display features are incomplete; thus in-depth study on ULTR is impossible such as the displayed abstract for analyzing the click necessary bias. Third, synthetic user feedback has been adopted by most existing datasets and real-world user feedback is greatly missing. To overcome these disadvantages, we introduce the Baidu-ULTR dataset. It involves randomly sampled 1.2 billion searching sessions and 7,008 expert annotated queries(397,572 query document pairs). Baidu-ULTR is the first billion-level dataset for ULTR. Particularly, it offers: (1)the original semantic features and pre-trained language models of different sizes; (2)sufficient display information such as position, displayed height, and displayed abstract, enabling the comprehensive study of multiple displayed biases; and (3)rich user feedback on search result pages (SERPs) like dwelling time, allowing for user engagement optimization and promoting the exploration of multi-task learning in …
[ Hall J ]

Generic motion understanding from video involves not only tracking objects, but also perceiving how their surfaces deform and move. This information is useful to make inferences about 3D shape, physical properties and object interactions. While the problem of tracking arbitrary physical points on surfaces over longer video clips has received some attention, no dataset or benchmark for evaluation existed, until now. In this paper, we first formalize the problem, naming it tracking any point (TAP). We introduce a companion benchmark,TAP-Vid, which is composed of both real-world videos with accurate human annotations of point tracks, and synthetic videos with perfect ground-truth point tracks. Central to the construction of our benchmark is a novel semi-automatic crowdsourced pipeline which uses optical flow estimates to compensate for easier, short-term motion like camera shake, allowing annotators to focus on harder sections of the video. We validate our pipeline on synthetic data and propose a simple end-to-end point tracking model, TAP-Net, showing that it outperforms all prior methods on our benchmark when trained on synthetic data.
[ Hall J ]
Joint visual and language modeling on large-scale datasets has recently shown good progress in multi-modal tasks when compared to single modal learning. However, robustness of these approaches against real-world perturbations has not been studied. In this work, we perform the first extensive robustness study of video-language models against various real-world perturbations. We focus on text-to-video retrieval and propose two large-scale benchmark datasets, MSRVTT-P and YouCook2-P, which utilize 90 different visual and 35 different text perturbations. The study reveals some interesting initial findings from the studied models: 1) models are more robust when text is perturbed versus when video is perturbed, 2) models that are pre-trained are more robust than those trained from scratch, 3) models attend more to scene and objects rather than motion and action. We hope this study will serve as a benchmark and guide future research in robust video-language learning. The benchmark introduced in this study along with the code and datasets is available at https://bit.ly/3CNOly4.
[ Hall J ]
The recent advances of deep learning have dramatically changed how machine learning, especially in the domain of natural language processing, can be applied to legal domain. However, this shift to the data-driven approaches calls for larger and more diverse datasets, which are nevertheless still small in number, especially in non-English languages. Here we present the first large-scale benchmark of Korean legal AI datasets, LBOX OPEN, that consists of one legal corpus, two classification tasks, two legal judgement prediction (LJP) tasks, and one summarization task. The legal corpus consists of 147k Korean precedents (259M tokens), of which 63k are sentenced in last 4 years and 96k are from the first and the second level courts in which factual issues are reviewed. The two classification tasks are case names (11.3k) and statutes (2.8k) prediction from the factual description of individual cases. The LJP tasks consist of (1) 10.5k criminal examples where the model is asked to predict fine amount, imprisonment with labor, and imprisonment without labor ranges for the given facts, and (2) 4.7k civil examples where the inputs are facts and claim for relief and outputs are the degrees of claim acceptance. The summarization task consists of the Supreme Court precedents …
[ Hall J ]
In the last years, neural networks (NN) have evolved from laboratory environments to the state-of-the-art for many real-world problems. It was shown that NN models (i.e., their weights and biases) evolve on unique trajectories in weight space during training. Following, a population of such neural network models (referred to as model zoo) would form structures in weight space. We think that the geometry, curvature and smoothness of these structures contain information about the state of training and can reveal latent properties of individual models. With such model zoos, one could investigate novel approaches for (i) model analysis, (ii) discover unknown learning dynamics, (iii) learn rich representations of such populations, or (iv) exploit the model zoos for generative modelling of NN weights and biases. Unfortunately, the lack of standardized model zoos and available benchmarks significantly increases the friction for further research about populations of NNs. With this work, we publish a novel dataset of model zoos containing systematically generated and diverse populations of NN models for further research. In total the proposed model zoo dataset is based on eight image datasets, consists of 27 model zoos trained with varying hyperparameter combinations and includes 50’360 unique NN models as well as their …
[ Hall J ]
Forecasting future world events is a challenging but valuable task. Forecasts of climate, geopolitical conflict, pandemics and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Given advances in language modeling, can these forecasts be automated? To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying news corpus. Questions are taken from forecasting tournaments, ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future). Motivated by the difficulty of forecasting numbers across orders of magnitude (e.g. global cases of COVID-19 in 2022), we also curate IntervalQA, a dataset of numerical questions and metrics for calibration. We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus. In sum, Autocast poses a novel challenge for large language models and improved performance could bring large practical benefits.
[ Hall J ]

Dataset Condensation is a newly emerging technique aiming at learning a tiny dataset that captures the rich information encoded in the original dataset. As the size of datasets contemporary machine learning models rely on becomes increasingly large, condensation methods become a prominent direction for accelerating network training and reducing data storage. Despite numerous methods have been proposed in this rapidly growing field, evaluating and comparing different condensation methods is non-trivial and still remains an open issue. The quality of condensed dataset are often shadowed by many critical contributing factors to the end performance, such as data augmentation and model architectures. The lack of a systematic way to evaluate and compare condensation methods not only hinders our understanding of existing techniques, but also discourages practical usage of the synthesized datasets. This work provides the first large-scale standardized benchmark on Dataset Condensation. It consists of a suite of evaluations to comprehensively reflect the generability and effectiveness of condensation methods through the lens of their generated dataset. Leveraging this benchmark, we conduct a large-scale study of current condensation methods, and report many insightful findings that open up new possibilities for future development. The benchmark library, including evaluators, baseline methods, and generated datasets, is …
[ Hall J ]

Surrogate models are necessary to optimize meaningful quantities in physical dynamics as their recursive numerical resolutions are often prohibitively expensive. It is mainly the case for fluid dynamics and the resolution of Navier–Stokes equations. However, despite the fast-growing field of data-driven models for physical systems, reference datasets representing real-world phenomena are lacking. In this work, we develop \textsc{AirfRANS}, a dataset for studying the two-dimensional incompressible steady-state Reynolds-Averaged Navier–Stokes equations over airfoils at a subsonic regime and for different angles of attacks. We also introduce metrics on the stress forces at the surface of geometries and visualization of boundary layers to assess the capabilities of models to accurately predict the meaningful information of the problem. Finally, we propose deep learning baselines on four machine learning tasks to study \textsc{AirfRANS} under different constraints for generalization considerations: big and scarce data regime, Reynolds number, and angle of attack extrapolation.
[ Hall J ]

Simulated humanoids are an appealing research domain due to their physical capabilities. Nonetheless, they are also challenging to control, as a policy must drive an unstable, discontinuous, and high-dimensional physical system. One widely studied approach is to utilize motion capture (MoCap) data to teach the humanoid agent low-level skills (e.g., standing, walking, and running) that can then be re-used to synthesize high-level behaviors. However, even with MoCap data, controlling simulated humanoids remains very hard, as MoCap data offers only kinematic information. Finding physical control inputs to realize the demonstrated motions requires computationally intensive methods like reinforcement learning. Thus, despite the publicly available MoCap data, its utility has been limited to institutions with large-scale compute. In this work, we dramatically lower the barrier for productive research on this topic by training and releasing high-quality agents that can track over three hours of MoCap data for a simulated humanoid in the dmcontrol physics-based environment. We release MoCapAct (Motion Capture with Actions), a dataset of these expert agents and their rollouts, which contain proprioceptive observations and actions. We demonstrate the utility of MoCapAct by using it to train a single hierarchical policy capable of tracking the entire MoCap dataset within dmcontrol …
[ Hall J ]
Cross-device federated learning is an emerging machine learning (ML) paradigm where a large population of devices collectively train an ML model while the data remains on the devices.This research field has a unique set of practical challenges, and to systematically make advances, new datasets curated to be compatible with this paradigm are needed.Existing federated learning benchmarks in the image domain do not accurately capture the scale and heterogeneity of many real-world use cases. We introduce FLAIR, a challenging large-scale annotated image dataset for multi-label classification suitable for federated learning.FLAIR has 429,078 images from 51,414 Flickr users and captures many of the intricacies typically encountered in federated learning, such as heterogeneous user data and a long-tailed label distribution.We implement multiple baselines in different learning setups for different tasks on this dataset. We believe FLAIR can serve as a challenging benchmark for advancing the state-of-the art in federated learning.Dataset access and the code for the benchmark are available at https://github.com/apple/ml-flair.
[ Hall J ]
In recent years, deep neural networks have demonstrated increasingly strong abilities to recognize objects and activities in videos. However, as video understanding becomes widely used in real-world applications, a key consideration is developing human-centric systems that understand not only the content of the video but also how it would affect the wellbeing and emotional state of viewers. To facilitate research in this setting, we introduce two large-scale datasets with over 60,000 videos manually annotated for emotional response and subjective wellbeing. The Video Cognitive Empathy (VCE) dataset contains annotations for distributions of fine-grained emotional responses, allowing models to gain a detailed understanding of affective states. The Video to Valence (V2V) dataset contains annotations of relative pleasantness between videos, which enables predicting a continuous spectrum of wellbeing. In experiments, we show how video models that are primarily trained to recognize actions and find contours of objects can be repurposed to understand human preferences and the emotional content of videos. Although there is room for improvement, predicting wellbeing and emotional response is on the horizon for state-of-the-art models. We hope our datasets can help foster further advances at the intersection of commonsense video understanding and human preference learning.
[ Hall J ]

We introduce the Multi-Agent Tracking Environment (MATE), a novel multi-agent environment simulates the target coverage control problems in the real world. MATE hosts an asymmetric cooperative-competitive game consisting of two groups of learning agents--"cameras" and "targets"--with opposing interests. Specifically, "cameras", a group of directional sensors, are mandated to actively control the directional perception area to maximize the coverage rate of targets. On the other side, "targets" are mobile agents that aim to transport cargo between multiple randomly assigned warehouses while minimizing the exposure to the camera sensor networks. To showcase the practicality of MATE, we benchmark the multi-agent reinforcement learning (MARL) algorithms from different aspects, including cooperation, communication, scalability, robustness, and asymmetric self-play. We start by reporting results for cooperative tasks using MARL algorithms (MAPPO, IPPO, QMIX, MADDPG) and the results after augmenting with multi-agent communication protocols (TarMAC, I2C). We then evaluate the effectiveness of the popular self-play techniques (PSRO, fictitious self-play) in an asymmetric zero-sum competitive game. This process of co-evolution between cameras and targets helps to realize a less exploitable camera network. We also observe the emergence of different roles of the target agents while incorporating I2C into target-target communication. MATE is written purely in Python and integrated …
[ Hall J ]
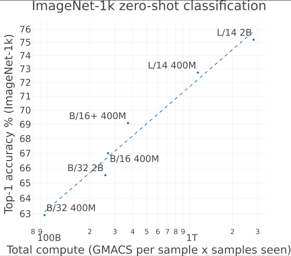
Groundbreaking language-vision architectures like CLIP and DALL-E proved the utility of training on large amounts of noisy image-text data, without relying on expensive accurate labels used in standard vision unimodal supervised learning. The resulting models showed capabilities of strong text-guided image generation and transfer to downstream tasks, while performing remarkably at zero-shot classification with noteworthy out-of-distribution robustness. Since then, large-scale language-vision models like ALIGN, BASIC, GLIDE, Flamingo and Imagen made further improvements. Studying the training and capabilities of such models requires datasets containing billions of image-text pairs. Until now, no datasets of this size have been made openly available for the broader research community. To address this problem and democratize research on large-scale multi-modal models, we present LAION-5B - a dataset consisting of 5.85 billion CLIP-filtered image-text pairs, of which 2.32B contain English language. We show successful replication and fine-tuning of foundational models like CLIP, GLIDE and Stable Diffusion using the dataset, and discuss further experiments enabled with an openly available dataset of this scale. Additionally we provide several nearest neighbor indices, an improved web-interface for dataset exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection.
[ Hall J ]

[ Hall J ]

[ Hall J ]
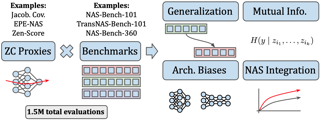
Zero-cost proxies (ZC proxies) are a recent architecture performance prediction technique aiming to significantly speed up algorithms for neural architecture search (NAS). Recent work has shown that these techniques show great promise, but certain aspects, such as evaluating and exploiting their complementary strengths, are under-studied. In this work, we create NAS-Bench-Suite: we evaluate 13 ZC proxies across 28 tasks, creating by far the largest dataset (and unified codebase) for ZC proxies, enabling orders-of-magnitude faster experiments on ZC proxies, while avoiding confounding factors stemming from different implementations. To demonstrate the usefulness of NAS-Bench-Suite, we run a large-scale analysis of ZC proxies, including a bias analysis, and the first information-theoretic analysis which concludes that ZC proxies capture substantial complementary information. Motivated by these findings, we present a procedure to improve the performance of ZC proxies by reducing biases such as cell size, and we also show that incorporating all 13 ZC proxies into the surrogate models used by NAS algorithms can improve their predictive performance by up to 42%. Our code and datasets are available at https://github.com/automl/naslib/tree/zerocost.
[ Hall J ]
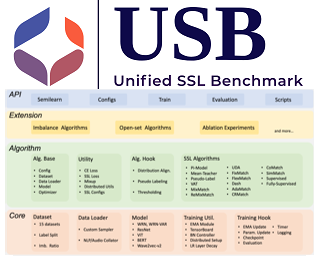
Semi-supervised learning (SSL) improves model generalization by leveraging massive unlabeled data to augment limited labeled samples. However, currently, popular SSL evaluation protocols are often constrained to computer vision (CV) tasks. In addition, previous work typically trains deep neural networks from scratch, which is time-consuming and environmentally unfriendly. To address the above issues, we construct a Unified SSL Benchmark (USB) for classification by selecting 15 diverse, challenging, and comprehensive tasks from CV, natural language processing (NLP), and audio processing (Audio), on which we systematically evaluate the dominant SSL methods, and also open-source a modular and extensible codebase for fair evaluation of these SSL methods. We further provide the pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning. USB enables the evaluation of a single SSL algorithm on more tasks from multiple domains but with less cost. Specifically, on a single NVIDIA V100, only 39 GPU days are required to evaluate FixMatch on 15 tasks in USB while 335 GPU days (279 GPU days on 4 CV datasets except for ImageNet) are needed on 5 CV tasks with TorchSSL.
[ Hall J ]

Video-language models (VLMs), large models pre-trained on numerous but noisy video-text pairs from the internet, have revolutionized activity recognition through their remarkable generalization and open-vocabulary capabilities. While complex human activities are often hierarchical and compositional, most existing tasks for evaluating VLMs focus only on high-level video understanding, making it difficult to accurately assess and interpret the ability of VLMs to understand complex and fine-grained human activities. Inspired by the recently proposed MOMA framework, we define activity graphs as a single universal representation of human activities that encompasses video understanding at the activity, sub-activity, and atomic action level. We redefine activity parsing as the overarching task of activity graph generation, requiring understanding human activities across all three levels. To facilitate the evaluation of models on activity parsing, we introduce MOMA-LRG (Multi-Object Multi-Actor Language-Refined Graphs), a large dataset of complex human activities with activity graph annotations that can be readily transformed into natural language sentences. Lastly, we present a model-agnostic and lightweight approach to adapting and evaluating VLMs by incorporating structured knowledge from activity graphs into VLMs, addressing the individual limitations of language and graphical models. We demonstrate strong performance on few-shot activity parsing, and our framework is intended to foster future …
[ Hall J ]
There has been a rapidly growing interest in Automatic Symptom Detection (ASD) and Automatic Diagnosis (AD) systems in the machine learning research literature, aiming to assist doctors in telemedicine services. These systems are designed to interact with patients, collect evidence about their symptoms and relevant antecedents, and possibly make predictions about the underlying diseases. Doctors would review the interactions, including the evidence and the predictions, collect if necessary additional information from patients, before deciding on next steps. Despite recent progress in this area, an important piece of doctors' interactions with patients is missing in the design of these systems, namely the differential diagnosis. Its absence is largely due to the lack of datasets that include such information for models to train on. In this work, we present a large-scale synthetic dataset of roughly 1.3 million patients that includes a differential diagnosis, along with the ground truth pathology, symptoms and antecedents for each patient. Unlike existing datasets which only contain binary symptoms and antecedents, this dataset also contains categorical and multi-choice symptoms and antecedents useful for efficient data collection. Moreover, some symptoms are organized in a hierarchy, making it possible to design systems able to interact with patients in a logical …
[ Hall J ]
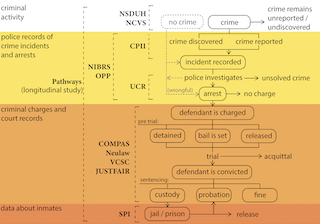
Criminal justice is an increasingly important application domain for machine learning and algorithmic fairness, as predictive tools are becoming widely used in police, courts, and prison systems worldwide. A few relevant benchmarks have received significant attention, e.g., the COMPAS dataset, often without proper consideration of the domain context. To raise awareness of publicly available criminal justice datasets and encourage their responsible use, we conduct a survey, consider contexts, highlight potential uses, and identify gaps and limitations. We provide datasheets for 15 datasets and upload them to a public repository. We compare the datasets across several dimensions, including size, coverage of the population, and potential use, highlighting concerns. We hope that this work can provide a useful starting point for researchers looking for appropriate datasets related to criminal justice, and that the repository will continue to grow as a community effort.
[ Hall J ]

Offline reinforcement learning (RL) aims at learning effective policies from historical data without extra environment interactions. During our experience of applying offline RL, we noticed that previous offline RL benchmarks commonly involve significant reality gaps, which we have identified include rich and overly exploratory datasets, degraded baseline, and missing policy validation. In many real-world situations, to ensure system safety, running an overly exploratory policy to collect various data is prohibited, thus only a narrow data distribution is available. The resulting policy is regarded as effective if it is better than the working behavior policy; the policy model can be deployed only if it has been well validated, rather than accomplished the training. In this paper, we present a Near real-world offline RL benchmark, named NeoRL, to reflect these properties. NeoRL datasets are collected with a more conservative strategy. Moreover, NeoRL contains the offline training and offline validation pipeline before the online test, corresponding to real-world situations. We then evaluate recent state-of-the-art offline RL algorithms in NeoRL. The empirical results demonstrate that some offline RL algorithms are less competitive to the behavior cloning and the deterministic behavior policy, implying that they could be less effective in real-world tasks than in the …
[ Hall J ]

This paper describes the OCCGEN toolkit, which allows extracting multilingual parallel data balanced in gender within occupations. OCCGEN can extract datasets that reflect gender diversity (beyond binary) more fairly in society to be further used to explicitly mitigate occupational gender stereotypes. We propose two use cases that extract evaluation datasets for machine translation in four high-resourcelanguages from different linguistic families and in a low-resource African language. Our analysis of these use cases shows that translation outputs in high-resource languages tend to worsen in feminine subsets (compared to masculine). This can be explained because less attention is paid to the source sentence. Then, more attention is given to the target prefix overgeneralizing to the most frequent masculine forms.
[ Hall J ]

Recording the dynamics of unscripted human interactions in the wild is challenging due to the delicate trade-offs between several factors: participant privacy, ecological validity, data fidelity, and logistical overheads. To address these, following a 'datasets for the community by the community' ethos, we propose the Conference Living Lab (ConfLab): a new concept for multimodal multisensor data collection of in-the-wild free-standing social conversations. For the first instantiation of ConfLab described here, we organized a real-life professional networking event at a major international conference. Involving 48 conference attendees, the dataset captures a diverse mix of status, acquaintance, and networking motivations. Our capture setup improves upon the data fidelity of prior in-the-wild datasets while retaining privacy sensitivity: 8 videos (1920x1080, 60 fps) from a non-invasive overhead view, and custom wearable sensors with onboard recording of body motion (full 9-axis IMU), privacy-preserving low-frequency audio (1250 Hz), and Bluetooth-based proximity. Additionally, we developed custom solutions for distributed hardware synchronization at acquisition, and time-efficient continuous annotation of body keypoints and actions at high sampling rates. Our benchmarks showcase some of the open research tasks related to in-the-wild privacy-preserving social data analysis: keypoints detection from overhead camera views, skeleton-based no-audio speaker detection, and F-formation detection.
[ Hall J ]
Proteomics is the interdisciplinary field focusing on the large-scale study of proteins. Proteins essentially organize and execute all functions within organisms. Today, the bottom-up analysis approach is the most commonly used workflow, where proteins are digested into peptides and subsequently analyzed using Tandem Mass Spectrometry (MS/MS). MS-based proteomics has transformed various fields in life sciences, such as drug discovery and biomarker identification. Today, proteomics is entering a phase where it is helpful for clinical decision-making. Computational methods are vital in turning large amounts of acquired raw MS data into information and, ultimately, knowledge. Deep learning has proved its success in multiple domains as a robust framework for supervised and unsupervised machine learning problems. In proteomics, scientists are increasingly leveraging the potential of deep learning to predict the properties of peptides based on their sequence to improve their confident identification. However, a reference dataset is missing, covering several proteomics tasks, enabling performance comparison, and evaluating reproducibility and generalization. Here, we present a large labeled proteomics dataset spanning several tasks in the domain to address this challenge. We focus on two common applications: peptide retention time and MS/MS spectrum prediction. We review existing methods and task formulations from a machine learning perspective …
[ Hall J ]
Accurate intraoperative diagnosis is essential for providing safe and effective care during brain tumor surgery. Our standard-of-care diagnostic methods are time, resource, and labor intensive, which restricts access to optimal surgical treatments. To address these limitations, we propose an alternative workflow that combines stimulated Raman histology (SRH), a rapid optical imaging method, with deep learning-based automated interpretation of SRH images for intraoperative brain tumor diagnosis and real-time surgical decision support. Here, we present OpenSRH, the first public dataset of clinical SRH images from 300+ brain tumors patients and 1300+ unique whole slide optical images. OpenSRH contains data from the most common brain tumors diagnoses, full pathologic annotations, whole slide tumor segmentations, raw and processed optical imaging data for end-to-end model development and validation. We provide a framework for patch-based whole slide SRH classification and inference using weak (i.e. patient-level) diagnostic labels. Finally, we benchmark two computer vision tasks: multi-class histologic brain tumor classification and patch-based contrastive representation learning. We hope OpenSRH will facilitate the clinical translation of rapid optical imaging and real-time ML-based surgical decision support in order to improve the access, safety, and efficacy of cancer surgery in the era of precision medicine.
[ Hall J ]

Proximal Policy Optimization (PPO) is a ubiquitous on-policy reinforcement learning algorithm but is significantly less utilized than off-policy learning algorithms in multi-agent settings. This is often due to the belief that PPO is significantly less sample efficient than off-policy methods in multi-agent systems. In this work, we carefully study the performance of PPO in cooperative multi-agent settings. We show that PPO-based multi-agent algorithms achieve surprisingly strong performance in four popular multi-agent testbeds: the particle-world environments, the StarCraft multi-agent challenge, the Hanabi challenge, and Google Research Football, with minimal hyperparameter tuning and without any domain-specific algorithmic modifications or architectures. Importantly, compared to competitive off-policy methods, PPO often achieves competitive or superior results in both final returns and sample efficiency. Finally, through ablation studies, we analyze implementation and hyperparameter factors that are critical to PPO's empirical performance, and give concrete practical suggestions regarding these factors. Our results show that when using these practices, simple PPO-based methods are a strong baseline in cooperative multi-agent reinforcement learning. Source code is released at https://github.com/marlbenchmark/on-policy.
[ Hall J ]

Extensive literature on backdoor poison attacks has studied attacks and defenses for backdoors using “digital trigger patterns.” In contrast, “physical backdoors” use physical objects as triggers, have only recently been identified, and are qualitatively different enough to resist most defenses targeting digital trigger backdoors. Research on physical backdoors is limited by access to large datasets containing real images of physical objects co-located with misclassification targets. Building these datasets is time- and labor-intensive.This work seeks to address the challenge of accessibility for research on physical backdoor attacks. We hypothesize that there may be naturally occurring physically co-located objects already present in popular datasets such as ImageNet. Once identified, a careful relabeling of these data can transform them into training samples for physical backdoor attacks. We propose a method to scalably identify these subsets of potential triggers in existing datasets, along with the specific classes they can poison. We call these naturally occurring trigger-class subsets natural backdoor datasets. Our techniques successfully identify natural backdoors in widely-available datasets, and produce models behaviorally equivalent to those trained on manually curated datasets. We release our code to allow the research community to create their own datasets for research on physical backdoor attacks.
[ Hall J ]
The ability to associate touch with sight is essential for tasks that require physically interacting with objects in the world. We propose a dataset with paired visual and tactile data called Touch and Go, in which human data collectors probe objects in natural environments using tactile sensors, while simultaneously recording egocentric video. In contrast to previous efforts, which have largely been confined to lab settings or simulated environments, our dataset spans a large number of “in the wild” objects and scenes. We successfully apply our dataset to a variety of multimodal learning tasks: 1) self-supervised visuo-tactile feature learning, 2) tactile-driven image stylization, i.e., making the visual appearance of an object more consistent with a given tactile signal, and 3) predicting future frames of a tactile signal from visuo-tactile inputs.
[ Hall J ]

While several types of post hoc explanation methods have been proposed in recent literature, there is very little work on systematically benchmarking these methods. Here, we introduce OpenXAI, a comprehensive and extensible open-source framework for evaluating and benchmarking post hoc explanation methods. OpenXAI comprises of the following key components: (i) a flexible synthetic data generator and a collection of diverse real-world datasets, pre-trained models, and state-of-the-art feature attribution methods, (ii) open-source implementations of twenty-two quantitative metrics for evaluating faithfulness, stability (robustness), and fairness of explanation methods, and (iii) the first ever public XAI leaderboards to readily compare several explanation methods across a wide variety of metrics, models, and datasets. OpenXAI is easily extensible, as users can readily evaluate custom explanation methods and incorporate them into our leaderboards. Overall, OpenXAI provides an automated end-to-end pipeline that not only simplifies and standardizes the evaluation of post hoc explanation methods, but also promotes transparency and reproducibility in benchmarking these methods. While the first release of OpenXAI supports only tabular datasets, the explanation methods and metrics that we consider are general enough to be applicable to other data modalities. OpenXAI datasets and data loaders, implementations of state-of-the-art explanation methods and evaluation metrics, as well …
[ Hall J ]

The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale radiance fields datasets for perception tasks, called the PeRFception, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4\%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take this radiance fields format as input and also propose a novel augmentation technique to avoid overfitting on backgrounds of images. The code and data are publicly available in "https://postech-cvlab.github.io/PeRFception/".
[ Hall J ]

Unsupervised Domain Adaptation demonstrates great potential to mitigate domain shifts by transferring models from labeled source domains to unlabeled target domains. While Unsupervised Domain Adaptation has been applied to a wide variety of complex vision tasks, only few works focus on lane detection for autonomous driving. This can be attributed to the lack of publicly available datasets. To facilitate research in these directions, we propose CARLANE, a 3-way sim-to-real domain adaptation benchmark for 2D lane detection. CARLANE encompasses the single-target datasets MoLane and TuLane and the multi-target dataset MuLane. These datasets are built from three different domains, which cover diverse scenes and contain a total of 163K unique images, 118K of which are annotated. In addition we evaluate and report systematic baselines, including our own method, which builds upon Prototypical Cross-domain Self-supervised Learning. We find that false positive and false negative rates of the evaluated domain adaptation methods are high compared to those of fully supervised baselines. This affirms the need for benchmarks such as CARLANE to further strengthen research in Unsupervised Domain Adaptation for lane detection. CARLANE, all evaluated models and the corresponding implementations are publicly available at https://carlanebenchmark.github.io.
[ Hall J ]
A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, there remains a major gap between humans and AI systems in terms of the sample efficiency with which they learn new visual reasoning tasks. Humans' remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality -- allowing them to efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and generating image datasets corresponding to these rules at scale. Our proposed benchmark includes measures of sample efficiency, generalization, compositionality, and transfer across task rules. We systematically evaluate modern neural architectures and find that convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are much …
[ Hall J ]
In our continuously evolving world, entities change over time and new, previously non-existing or unknown, entities appear. We study how this evolutionary scenario impacts the performance on a well established entity linking (EL) task. For that study, we introduce TempEL, an entity linking dataset that consists of time-stratified English Wikipedia snapshots from 2013 to 2022, from which we collect both anchor mentions of entities, and these target entities’ descriptions. By capturing such temporal aspects, our newly introduced TempEL resource contrasts with currently existing entity linking datasets, which are composed of fixed mentions linked to a single static version of a target Knowledge Base (e.g., Wikipedia 2010 for CoNLL-AIDA). Indeed, for each of our collected temporal snapshots, TempEL contains links to entities that are continual, i.e., occur in all of the years, as well as completely new entities that appear for the first time at some point. Thus, we enable to quantify the performance of current state-of-the-art EL models for: (i) entities that are subject to changes over time in their Knowledge Base descriptions as well as their mentions’ contexts, and (ii) newly created entities that were previously non-existing (e.g., at the time the EL model was trained). Our experimental results …
[ Hall J ]
[ Hall J ]
Weak supervision (WS) is a powerful method to build labeled datasets for training supervised models in the face of little-to-no labeled data. It replaces hand-labeling data with aggregating multiple noisy-but-cheap label estimates expressed by labeling functions (LFs). While it has been used successfully in many domains, weak supervision's application scope is limited by the difficulty of constructing labeling functions for domains with complex or high-dimensional features. To address this, a handful of methods have proposed automating the LF design process using a small set of ground truth labels. In this work, we introduce AutoWS-Bench-101: a framework for evaluating automated WS (AutoWS) techniques in challenging WS settings---a set of diverse application domains on which it has been previously difficult or impossible to apply traditional WS techniques. While AutoWS is a promising direction toward expanding the application-scope of WS, the emergence of powerful methods such as zero-shot foundation models reveal the need to understand how AutoWS techniques compare or cooperate with modern zero-shot or few-shot learners. This informs the central question of AutoWS-Bench-101: given an initial set of 100 labels for each task, we ask whether a practitioner should use an AutoWS method to generate additional labels or use some simpler baseline, …
[ Hall J ]
In recent years there has been significant progress in the field of 3D learning on classification, detection and segmentation problems. The vast majority of the existing studies focus on canonical closed-set conditions, neglecting the intrinsic open nature of the real-world. This limits the abilities of robots and autonomous systems involved in safety-critical applications that require managing novel and unknown signals. In this context exploiting 3D data can be a valuable asset since it provides rich information about the geometry of perceived objects and scenes. With this paper we provide the first broad study on 3D Open Set learning. We introduce 3DOS: a novel testbed for semantic novelty detection that considers several settings with increasing difficulties in terms of semantic (category) shift, and covers both in-domain (synthetic-to-synthetic, real-to-real) and cross-domain (synthetic-to-real) scenarios. Moreover, we investigate the related 2D Open Set literature to understand if and how its recent improvements are effective on 3D data. Our extensive benchmark positions several algorithms in the same coherent picture, revealing their strengths and limitations. The results of our analysis may serve as a reliable foothold for future tailored 3D Open Set methods.
[ Hall J ]
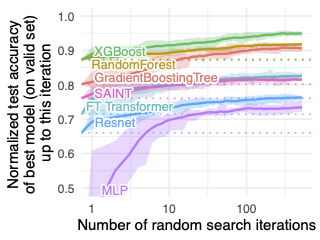
[ Hall J ]
The Dark Web represents a hotbed for illicit activity, where users communicate on different market forums in order to exchange goods and services. Law enforcement agencies benefit from forensic tools that perform authorship analysis, in order to identify and profile users based on their textual content. However, authorship analysis has been traditionally studied using corpora featuring literary texts such as fragments from novels or fan fiction, which may not be suitable in a cybercrime context. Moreover, the few works that employ authorship analysis tools for cybercrime prevention usually employ ad-hoc experimental setups and datasets. To address these issues, we release VeriDark: a benchmark comprised of three large scale authorship verification datasets and one authorship identification dataset obtained from user activity from either Dark Web related Reddit communities or popular illicit Dark Web market forums. We evaluate competitive NLP baselines on the three datasets and perform an analysis of the predictions to better understand the limitations of such approaches. We make the datasets and baselines publicly available at https://github.com/bit-ml/VeriDark .
[ Hall J ]

[ Hall J ]
Euclidean geometry is among the earliest forms of mathematical thinking. While the geometric primitives underlying its constructions, such as perfect lines and circles, do not often occur in the natural world, humans rarely struggle to perceive and reason with them. Will computer vision models trained on natural images show the same sensitivity to Euclidean geometry? Here we explore these questions by studying few-shot generalization in the universe of Euclidean geometry constructions. We introduce Geoclidean, a domain-specific language for Euclidean geometry, and use it to generate two datasets of geometric concept learning tasks for benchmarking generalization judgements of humans and machines. We find that humans are indeed sensitive to Euclidean geometry and generalize strongly from a few visual examples of a geometric concept. In contrast, low-level and high-level visual features from standard computer vision models pretrained on natural images do not support correct generalization. Thus Geoclidean represents a novel few-shot generalization benchmark for geometric concept learning, where the performance of humans and of AI models diverge. The Geoclidean framework and dataset are publicly available for download.
[ Hall J ]
Unlike RGB cameras that use visible light bands (384∼769 THz) and Lidars that use infrared bands (361∼331 THz), Radars use relatively longer wavelength radio bands (77∼81 GHz), resulting in robust measurements in adverse weathers. Unfortunately, existing Radar datasets only contain a relatively small number of samples compared to the existing camera and Lidar datasets. This may hinder the development of sophisticated data-driven deep learning techniques for Radar-based perception. Moreover, most of the existing Radar datasets only provide 3D Radar tensor (3DRT) data that contain power measurements along the Doppler, range, and azimuth dimensions. As there is no elevation information, it is challenging to estimate the 3D bounding box of an object from 3DRT. In this work, we introduce KAIST-Radar (K-Radar), a novel large-scale object detection dataset and benchmark that contains 35K frames of 4D Radar tensor (4DRT) data with power measurements along the Doppler, range, azimuth, and elevation dimensions, together with carefully annotated 3D bounding box labels of objects on the roads. K-Radar includes challenging driving conditions such as adverse weathers (fog, rain, and snow) on various road structures (urban, suburban roads, alleyways, and highways). In addition to the 4DRT, we provide auxiliary measurements from carefully calibrated high-resolution Lidars, surround …
[ Hall J ]

We are now witnessing significant progress of deep learning methods in a variety of tasks (or datasets) of proteins. However, there is a lack of a standard benchmark to evaluate the performance of different methods, which hinders the progress of deep learning in this field. In this paper, we propose such a benchmark called PEER, a comprehensive and multi-task benchmark for Protein sEquence undERstanding. PEER provides a set of diverse protein understanding tasks including protein function prediction, protein localization prediction, protein structure prediction, protein-protein interaction prediction, and protein-ligand interaction prediction. We evaluate different types of sequence-based methods for each task including traditional feature engineering approaches, different sequence encoding methods as well as large-scale pre-trained protein language models. In addition, we also investigate the performance of these methods under the multi-task learning setting. Experimental results show that large-scale pre-trained protein language models achieve the best performance for most individual tasks, and jointly training multiple tasks further boosts the performance. The datasets and source codes of this benchmark will be open-sourced soon.
[ Hall J ]

Physical simulations are at the core of many critical industrial systems. However, today's physical simulators have some limitations such as computation time, dealing with missing or uncertain data, or even non-convergence for some feasible cases. Recently, the use of data-driven approaches to learn complex physical simulations has been considered as a promising approach to address those issues. However, this comes often at the cost of some accuracy which may hinder the industrial use. To drive this new research topic towards a better real-world applicability, we propose a new benchmark suite "Learning Industrial Physical Simulations"(LIPS) to meet the need of developing efficient, industrial application-oriented, augmented simulators. To define how to assess such benchmark performance, we propose a set of four generic categories of criteria. The proposed benchmark suite is a modular and configurable framework that can deal with different physical problems. To demonstrate this ability, we propose in this paper to investigate two distinct use-cases with different physical simulations, namely: the power grid and the pneumatic. For each use case, several benchmarks are described and assessed with existing models. None of the models perform well under all expected criteria, inviting the community to develop new industry-applicable solutions and possibly showcase their …
[ Hall J ]

We introduce SoundSpaces 2.0, a platform for on-the-fly geometry-based audio rendering for 3D environments. Given a 3D mesh of a real-world environment, SoundSpaces can generate highly realistic acoustics for arbitrary sounds captured from arbitrary microphone locations. Together with existing 3D visual assets, it supports an array of audio-visual research tasks, such as audio-visual navigation, mapping, source localization and separation, and acoustic matching. Compared to existing resources, SoundSpaces 2.0 has the advantages of allowing continuous spatial sampling, generalization to novel environments, and configurable microphone and material properties. To our knowledge, this is the first geometry-based acoustic simulation that offers high fidelity and realism while also being fast enough to use for embodied learning. We showcase the simulator's properties and benchmark its performance against real-world audio measurements. In addition, we demonstrate two downstream tasks---embodied navigation and far-field automatic speech recognition---and highlight sim2real performance for the latter. SoundSpaces 2.0 is publicly available to facilitate wider research for perceptual systems that can both see and hear.
[ Hall J ]
[ Hall J ]
Estimating personalized effects of treatments is a complex, yet pervasive problem. To tackle it, recent developments in the machine learning (ML) literature on heterogeneous treatment effect estimation gave rise to many sophisticated, but opaque, tools: due to their flexibility, modularity and ability to learn constrained representations, neural networks in particular have become central to this literature. Unfortunately, the assets of such black boxes come at a cost: models typically involve countless nontrivial operations, making it difficult to understand what they have learned. Yet, understanding these models can be crucial -- in a medical context, for example, discovered knowledge on treatment effect heterogeneity could inform treatment prescription in clinical practice. In this work, we therefore use post-hoc feature importance methods to identify features that influence the model's predictions. This allows us to evaluate treatment effect estimators along a new and important dimension that has been overlooked in previous work: We construct a benchmarking environment to empirically investigate the ability of personalized treatment effect models to identify predictive covariates -- covariates that determine differential responses to treatment. Our benchmarking environment then enables us to provide new insight into the strengths and weaknesses of different types of treatment effects models as we modulate …
[ Hall J ]
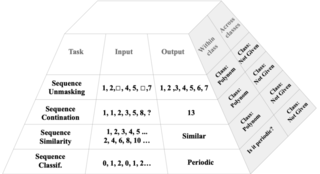
Integer sequences are of central importance to the modeling of concepts admitting complete finitary descriptions. We introduce a novel view on the learning of such concepts and lay down a set of benchmarking tasks aimed at conceptual understanding by machine learning models. These tasks indirectly assess model ability to abstract, and challenge them to reason both interpolatively and extrapolatively from the knowledge gained by observing representative examples. To further aid research in knowledge representation and reasoning, we present FACT, the Finitary Abstraction Comprehension Toolkit. The toolkit surrounds a large dataset of integer sequences comprising both organic and synthetic entries, a library for data pre-processing and generation, a set of model performance evaluation tools, and a collection of baseline model implementations, enabling the making of the future advancements with ease.
[ Hall J ]

Satellite imagery is increasingly available, high resolution, and temporally detailed. Changes in spatio-temporal datasets such as satellite images are particularly interesting as they reveal the many events and forces that shape our world. However, finding such interesting and meaningful change events from the vast data is challenging. In this paper, we present new datasets for such change events that include semantically meaningful events like road construction. Instead of manually annotating the very large corpus of satellite images, we introduce a novel unsupervised approach that takes a large spatio-temporal dataset from satellite images and finds interesting change events. To evaluate the meaningfulness on these datasets we create 2 benchmarks namely CaiRoad and CalFire which capture the events of road construction and forest fires. These new benchmarks can be used to evaluate semantic retrieval/classification performance. We explore these benchmarks qualitatively and quantitatively by using several methods and show that these new datasets are indeed challenging for many existing methods.
[ Hall J ]
Commercial ML APIs offered by providers such as Google, Amazon and Microsoft have dramatically simplified ML adoptions in many applications. Numerous companies and academics pay to use ML APIs for tasks such as object detection, OCR and sentiment analysis. Different ML APIs tackling the same task can have very heterogeneous performances. Moreover, the ML models underlying the APIs also evolve over time. As ML APIs rapidly become a valuable marketplace and an integral part of analytics, it is critical to systematically study and compare different APIs with each other and to characterize how individual APIs change over time. However, this practically important topic is currently underexplored due to the lack of data. In this paper, we present HAPI (History of APIs), a longitudinal dataset of 1,761,417 instances of commercial ML API applications (involving APIs from Amazon, Google, IBM, Microsoft and other providers) across diverse tasks including image tagging, speech recognition, and text mining from 2020 to 2022. Each instance consists of a query input for an API (e.g., an image or text) along with the API’s output prediction/annotation and confidence scores. HAPI is the first large-scale dataset of ML API usages and is a unique resource for studying ML as-a-service …
[ Hall J ]
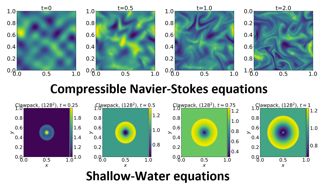
Machine learning-based modeling of physical systems has experienced increased interest in recent years. Despite some impressive progress, there is still a lack of benchmarks for Scientific ML that are easy to use but still challenging and repre- sentative of a wide range of problems. We introduce PDEBENCH, a benchmark suite of time-dependent simulation tasks based on Partial Differential Equations (PDEs). PDEBENCH comprises both code and data to benchmark the performance of novel machine learning models against both classical numerical simulations and machine learning baselines. Our proposed set of benchmark problems con- tribute the following unique features: (1) A much wider range of PDEs compared to existing benchmarks, ranging from relatively common examples to more real- istic and difficult problems; (2) much larger ready-to-use datasets compared to prior work, comprising multiple simulation runs across a larger number of ini- tial and boundary conditions and PDE parameters; (3) more extensible source codes with user-friendly APIs for data generation and baseline results with popular machine learning models (FNO, U-Net, PINN, Gradient-Based Inverse Method). PDEBENCH allows researchers to extend the benchmark freely for their own pur- poses using a standardized API and to compare the performance of new models to existing baseline methods. We …
[ Hall J ]

[ Hall J ]

We introduce VISOR, a new dataset of pixel annotations and a benchmark suite for segmenting hands and active objects in egocentric video. VISOR annotates videos from EPIC-KITCHENS, which comes with a new set of challenges not encountered in current video segmentation datasets. Specifically, we need to ensure both short- and long-term consistency of pixel-level annotations as objects undergo transformative interactions, e.g. an onion is peeled, diced and cooked - where we aim to obtain accurate pixel-level annotations of the peel, onion pieces, chopping board, knife, pan, as well as the acting hands. VISOR introduces an annotation pipeline, AI-powered in parts, for scalability and quality. In total, we publicly release 272K manual semantic masks of 257 object classes, 9.9M interpolated dense masks, 67K hand-object relations, covering 36 hours of 179 untrimmed videos. Along with the annotations, we introduce three challenges in video object segmentation, interaction understanding and long-term reasoning.For data, code and leaderboards: http://epic-kitchens.github.io/VISOR
[ Hall J ]
The use of cameras and computational algorithms for noninvasive, low-cost and scalable measurement of physiological (e.g., cardiac and pulmonary) vital signs is very attractive. However, diverse data representing a range of environments, body motions, illumination conditions and physiological states is laborious, time consuming and expensive to obtain. Synthetic data have proven a valuable tool in several areas of machine learning, yet are not widely available for camera measurement of physiological states. Synthetic data offer "perfect" labels (e.g., without noise and with precise synchronization), labels that may not be possible to obtain otherwise (e.g., precise pixel level segmentation maps) and provide a high degree of control over variation and diversity in the dataset. We present SCAMPS, a dataset of synthetics containing 2,800 videos (1.68M frames) with aligned cardiac and respiratory signals and facial action intensities. The RGB frames are provided alongside segmentation maps and precise descriptive statistics about the underlying waveforms, including inter-beat interval, heart rate variability, and pulse arrival time. Finally, we present baseline results training on these synthetic data and testing on real-world datasets to illustrate generalizability.
[ Hall J ]

Understanding human tasks through video observations is an essential capability of intelligent agents. The challenges of such capability lie in the difficulty of generating a detailed understanding of situated actions, their effects on object states (\ie, state changes), and their causal dependencies. These challenges are further aggravated by the natural parallelism from multi-tasking and partial observations in multi-agent collaboration. Most prior works leverage action localization or future prediction as an \textit{indirect} metric for evaluating such task understanding from videos. To make a \textit{direct} evaluation, we introduce the EgoTaskQA benchmark that provides a single home for the crucial dimensions of task understanding through question answering on real-world egocentric videos. We meticulously design questions that target the understanding of (1) action dependencies and effects, (2) intents and goals, and (3) agents' beliefs about others. These questions are divided into four types, including descriptive (what status?), predictive (what will?), explanatory (what caused?), and counterfactual (what if?) to provide diagnostic analyses on \textit{spatial, temporal, and causal} understandings of goal-oriented tasks. We evaluate state-of-the-art video reasoning models on our benchmark and show their significant gaps between humans in understanding complex goal-oriented egocentric videos. We hope this effort would drive the vision community to move onward …
[ Hall J ]

High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to allow researchers to investigate and quantify the impact of such data quality issues. With the benchmark we can study the impact of annotation costs and (semi-)supervised methods on the data quality for image classification by applying a novel methodology to a range of different algorithms and diverse datasets. Our benchmark uses a two-phase approach via a data label improvement method in the first phase and a fixed evaluation model in the second phase. Thereby, we give a measure for the relation between the input labeling effort and the performance of (semi-)supervised algorithms to enable a deeper insight into how labels should be created for effective model training. Across thousands of experiments, we show that one annotation is not enough and that the inclusion of multiple annotations allows for a better approximation of the real underlying class distribution. We identify that hard …
[ Hall J ]
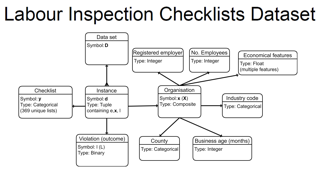
Among United Nations' 17 Sustainable Development Goals (SDGs), we highlight SDG 8 on Decent Work and Economic Growth. Specifically, we consider how to achieve subgoal 8.8, "protect labour rights and promote safe working environments for all workers [...]", in light of poor health, safety and environment (HSE) conditions being a widespread problem at workplaces. In EU alone, it is estimated that more than 4000 deaths occur each year due to poor working conditions. To handle the problem and achieve SDG 8, governmental agencies conduct labour inspections and it is therefore essential that these are carried out efficiently. Current research suggests that machine learning (ML) can be used to improve labour inspections, for instance by selecting organisations for inspections more effectively. However, the research in this area is very limited, in part due to a lack of publicly available data. Consequently, we introduce a new dataset called the Labour Inspection Checklists Dataset (LICD), which we have made publicly available. LICD consists of 63634 instances where each instance is an inspection conducted by the Norwegian Labour Inspection Authority. LICD has 577 features and labels. The dataset provides several ML research opportunities; we discuss two demonstration experiments. One experiment deals with the problem …
[ Hall J ]

Contemporary vision benchmarks predominantly consider tasks on which humans can achieve near-perfect performance. However, humans are frequently presented with visual data that they cannot classify with 100% certainty, and models trained on standard vision benchmarks achieve low performance when evaluated on this data. To address this issue, we introduce a procedure for creating datasets of ambiguous images and use it to produce SQUID-E ("Squidy"), a collection of noisy images extracted from videos. All images are annotated with ground truth values and a test set is annotated with human uncertainty judgments. We use this dataset to characterize human uncertainty in vision tasks and evaluate existing visual event classification models. Experimental results suggest that existing vision models are not sufficiently equipped to provide meaningful outputs for ambiguous images and that datasets of this nature can be used to assess and improve such models through model training and direct evaluation of model calibration. These findings motivate large-scale ambiguous dataset creation and further research focusing on noisy visual data.
[ Hall J ]
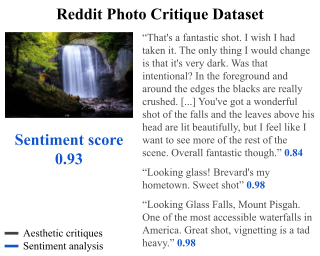
Computational inference of aesthetics is an ill-defined task due to its subjective nature. Many datasets have been proposed to tackle the problem by providing pairs of images and aesthetic scores based on human ratings. However, humans are better at expressing their opinion, taste, and emotions by means of language rather than summarizing them in a single number. In fact, photo critiques provide much richer information as they reveal how and why users rate the aesthetics of visual stimuli. In this regard, we propose the Reddit Photo Critique Dataset (RPCD), which contains tuples of image and photo critiques. RPCD consists of 74K images and 220K comments and is collected from a Reddit community used by hobbyists and professional photographers to improve their photography skills by leveraging constructive community feedback. The proposed dataset differs from previous aesthetics datasets mainly in three aspects, namely (i) the large scale of the dataset and the extension of the comments criticizing different aspects of the image, (ii) it contains mostly UltraHD images, and (iii) it can easily be extended to new data as it is collected through an automatic pipeline. To the best of our knowledge, in this work, we propose the first attempt to estimate …
[ Hall J ]
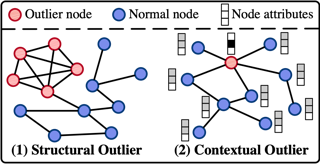
Detecting which nodes in graphs are outliers is a relatively new machine learning task with numerous applications. Despite the proliferation of algorithms developed in recent years for this task, there has been no standard comprehensive setting for performance evaluation. Consequently, it has been difficult to understand which methods work well and when under a broad range of settings. To bridge this gap, we present—to the best of our knowledge—the first comprehensive benchmark for unsupervised outlier node detection on static attributed graphs called BOND, with the following highlights. (1) We benchmark the outlier detection performance of 14 methods ranging from classical matrix factorization to the latest graph neural networks. (2) Using nine real datasets, our benchmark assesses how the different detection methods respond to two major types of synthetic outliers and separately to “organic” (real non-synthetic) outliers. (3) Using an existing random graph generation technique, we produce a family of synthetically generated datasets of different graph sizes that enable us to compare the running time and memory usage of the different outlier detection algorithms. Based on our experimental results, we discuss the pros and cons of existing graph outlier detection algorithms, and we highlight opportunities for future research. Importantly, our code …
[ Hall J ]
In recent years, deep generative models have attracted increasing interest due to their capacity to model complex distributions. Among those models, variational autoencoders have gained popularity as they have proven both to be computationally efficient and yield impressive results in multiple fields. Following this breakthrough, extensive research has been done in order to improve the original publication, resulting in a variety of different VAE models in response to different tasks. In this paper we present \textbf{Pythae}, a versatile \textit{open-source} Python library providing both a \textit{unified implementation} and a dedicated framework allowing \textit{straightforward}, \emph{reproducible} and \textit{reliable} use of generative autoencoder models. We then propose to use this library to perform a case study benchmark where we present and compare 19 generative autoencoder models representative of some of the main improvements on downstream tasks such as image reconstruction, generation, classification, clustering and interpolation. The open-source library can be found at \url{https://github.com/clementchadebec/benchmark_VAE}.
[ Hall J ]
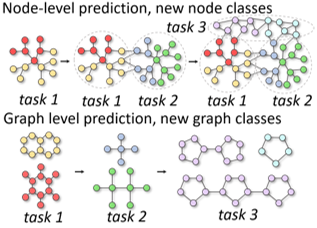
[ Hall J ]

[ Hall J ]

Recent breakthroughs in the development of agents to solve challenging sequential decision making problems such as Go, StarCraft, or DOTA, have relied on both simulated environments and large-scale datasets. However, progress on this research has been hindered by the scarcity of open-sourced datasets and the prohibitive computational cost to work with them. Here we present the NetHack Learning Dataset (NLD), a large and highly-scalable dataset of trajectories from the popular game of NetHack, which is both extremely challenging for current methods and very fast to run. NLD consists of three parts: 10 billion state transitions from 1.5 million human trajectories collected on the NAO public NetHack server from 2009 to 2020; 3 billion state-action-score transitions from 100,000 trajectories collected from the symbolic bot winner of the NetHack Challenge 2021; and, accompanying code for users to record, load and stream any collection of such trajectories in a highly compressed form. We evaluate a wide range of existing algorithms for learning from demonstrations, showing that significant research advances are needed to fully leverage large-scale datasets for challenging sequential decision making tasks.
[ Hall J ]
This paper introduces Honor of Kings Arena, a reinforcement learning (RL) environment based on the Honor of Kings, one of the world’s most popular games at present. Compared to other environments studied in most previous work, ours presents new generalization challenges for competitive reinforcement learning. It is a multi-agent problem with one agent competing against its opponent; and it requires the generalization ability as it has diverse targets to control and diverse opponents to compete with. We describe the observation, action, and reward specifications for the Honor of Kings domain and provide an open-source Python-based interface for communicating with the game engine. We provide twenty target heroes with a variety of tasks in Honor of Kings Arena and present initial baseline results for RL-based methods with feasible computing resources. Finally, we showcase the generalization challenges imposed by Honor of Kings Arena and possible remedies to the challenges. All of the software, including the environment-class, are publicly available.
[ Hall J ]

[ Hall J ]

Training and evaluating language models increasingly requires the construction of meta-datasets -- diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a variety of novel instruction tuning tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBio a community library of 126+ biomedical NLP datasets, currently covering 13 task categories and 10+ languages. BigBio facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBio is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical
[ Hall J ]
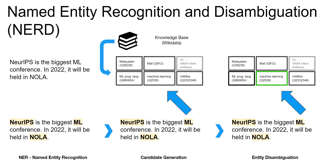
Named Entity Recognition and Disambiguation (NERD) systems are foundational for information retrieval, question answering, event detection, and other natural language processing (NLP) applications. We introduce TweetNERD, a dataset of 340K+ Tweets across 2010-2021, for benchmarking NERD systems on Tweets. This is the largest and most temporally diverse open sourced dataset benchmark for NERD on Tweets and can be used to facilitate research in this area. We describe evaluation setup with TweetNERD for three NERD tasks: Named Entity Recognition (NER), Entity Linking with True Spans (EL), and End to End Entity Linking (End2End); and provide performance of existing publicly available methods on specific TweetNERD splits. TweetNERD is available at: https://doi.org/10.5281/zenodo.6617192 under Creative Commons Attribution 4.0 International (CC BY 4.0) license. Check out more details at https://github.com/twitter-research/TweetNERD.
[ Hall J ]
For the deployment of artificial intelligence (AI) in high risk settings, such as healthcare, methods that provide interpretability/explainability or allow fine-grained error analysis are critical. Many recent methods for interpretability/explainability and fine-grained error analysis use concepts, which are meta-labels which are semantically meaningful to humans. However, there are only a few datasets that include concept-level meta-labels and most of these meta-labels are relevant for natural images that do not require domain expertise. Previous densely annotated datasets in medicine focused on meta-labels that are relevant to a single disease such as osteoarthritis or melanoma. In dermatology, skin disease is described using an established clinical lexicon that allow clinicians to describe physical exam findings to one another. To provide the first medical dataset densely annotated by domain experts to provide annotations useful across multiple disease processes, we developed SkinCon: a skin disease dataset densely annotated by dermatologists. SkinCon includes 3230 images from the Fitzpatrick 17k skin disease dataset densely annotated with 48 clinical concepts, 22 of which have at least 50 images representing the concept. The concepts used were chosen by two dermatologists considering the clinical descriptor terms used to describe skin lesions. Examples include "plaque", "scale", and "erosion". These same concepts …
[ Hall J ]

Post-processing ensemble prediction systems can improve the reliability of weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of weather post-processing. However, these models require a comprehensive dataset of weather simulations to produce high-accuracy results, which comes at a high computational cost to generate. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spanning 20 years (1998--2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables at 11 distinct pressure levels and the surface at \ang{0.5} resolution for forecast lead times T=0, 24, and 48 hours (two data points per week). We propose the ENS-10 prediction correction task for improving the forecast quality at a 48-hour lead time through ensemble post-processing. We provide a set of baselines and compare their skill at correcting the predictions of three important atmospheric variables. Moreover, we measure the baselines' skill at improving predictions of extreme weather events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) license.
[ Hall J ]

Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains challenging to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will publicly release ELEVATER.
[ Hall J ]
Building machines that can reason about physical events and their causal relationships is crucial for flexible interaction with the physical world. However, most existing physical and causal reasoning benchmarks are exclusively based on synthetically generated events and synthetic natural language descriptions of the causal relationships. This design brings up two issues. First, there is a lack of diversity in both event types and natural language descriptions; second, causal relationships based on manually-defined heuristics are different from human judgments. To address both shortcomings, we present the CLEVRER-Humans benchmark, a video reasoning dataset for causal judgment of physical events with human labels. We employ two techniques to improve data collection efficiency: first, a novel iterative event cloze task to elicit a new representation of events in videos, which we term Causal Event Graphs (CEGs); second, a data augmentation technique based on neural language generative models. We convert the collected CEGs into questions and answers to be consistent with prior work. Finally, we study a collection of baseline approaches for CLEVRER-Humans question-answering, highlighting great challenges set forth by our benchmark.
[ Hall J ]

Given a long list of anomaly detection algorithms developed in the last few decades, how do they perform with regard to (i) varying levels of supervision, (ii) different types of anomalies, and (iii) noisy and corrupted data? In this work, we answer these key questions by conducting (to our best knowledge) the most comprehensive anomaly detection benchmark with 30 algorithms on 57 benchmark datasets, named ADBench. Our extensive experiments (98,436 in total) identify meaningful insights into the role of supervision and anomaly types, and unlock future directions for researchers in algorithm selection and design. With ADBench, researchers can easily conduct comprehensive and fair evaluations for newly proposed methods on the datasets (including our contributed ones from natural language and computer vision domains) against the existing baselines. To foster accessibility and reproducibility, we fully open-source ADBench and the corresponding results.
[ Hall J ]

Video-quality measurement is a critical task in video processing. Nowadays, many implementations of new encoding standards - such as AV1, VVC, and LCEVC - use deep-learning-based decoding algorithms with perceptual metrics that serve as optimization objectives. But investigations of the performance of modern video- and image-quality metrics commonly employ videos compressed using older standards, such as AVC. In this paper, we present a new benchmark for video-quality metrics that evaluates video compression. It is based on a new dataset consisting of about 2,500 streams encoded using different standards, including AVC, HEVC, AV1, VP9, and VVC. Subjective scores were collected using crowdsourced pairwise comparisons. The list of evaluated metrics includes recent ones based on machine learning and neural networks. The results demonstrate that new no-reference metrics exhibit high correlation with subjective quality and approach the capability of top full-reference metrics.
[ Hall J ]

[ Hall J ]
Clinical diagnosis of the eye is performed over multifarious data modalities including scalar clinical labels, vectorized biomarkers, two-dimensional fundus images, and three-dimensional Optical Coherence Tomography (OCT) scans. Clinical practitioners use all available data modalities for diagnosing and treating eye diseases like Diabetic Retinopathy (DR) or Diabetic Macular Edema (DME). Enabling usage of machine learning algorithms within the ophthalmic medical domain requires research into the relationships and interactions between all relevant data over a treatment period. Existing datasets are limited in that they neither provide data nor consider the explicit relationship modeling between the data modalities. In this paper, we introduce the Ophthalmic Labels for Investigating Visual Eye Semantics (OLIVES) dataset that addresses the above limitation. This is the first OCT and near-IR fundus dataset that includes clinical labels, biomarker labels, disease labels, and time-series patient treatment information from associated clinical trials. The dataset consists of 1268 near-IR fundus images each with at least 49 OCT scans, and 16 biomarkers, along with 4 clinical labels and a disease diagnosis of DR or DME. In total, there are 96 eyes' data averaged over a period of at least two years with each eye treated for an average of 66 weeks and 7 …
[ Hall J ]
Current state-of-the-art vision-and-language models are evaluated on tasks either individually or in a multi-task setting, overlooking the challenges of continually learning (CL) tasks as they arrive. Existing CL benchmarks have facilitated research on task adaptation and mitigating "catastrophic forgetting", but are limited to vision-only and language-only tasks. We present CLiMB, a benchmark to study the challenge of learning multimodal tasks in a CL setting, and to systematically evaluate how upstream continual learning can rapidly generalize to new multimodal and unimodal tasks. CLiMB includes implementations of several CL algorithms and a modified Vision-Language Transformer (ViLT) model that can be deployed on both multimodal and unimodal tasks. We find that common CL methods can help mitigate forgetting during multimodal task learning, but do not enable cross-task knowledge transfer. We envision that CLiMB will facilitate research on a new class of CL algorithms for this challenging multimodal setting.
[ Hall J ]
Facial analysis systems have been deployed by large companies and critiqued by scholars and activists for the past decade. Many existing algorithmic audits examine the performance of these systems on later stage elements of facial analysis systems like facial recognition and age, emotion, or perceived gender prediction; however, a core component to these systems has been vastly understudied from a fairness perspective: face detection, sometimes called face localization. Since face detection is a pre-requisite step in facial analysis systems, the bias we observe in face detection will flow downstream to the other components like facial recognition and emotion prediction. Additionally, no prior work has focused on the robustness of these systems under various perturbations and corruptions, which leaves open the question of how various people are impacted by these phenomena. We present the first of its kind detailed benchmark of face detection systems, specifically examining the robustness to noise of commercial and academic models. We use both standard and recently released academic facial datasets to quantitatively analyze trends in face detection robustness. Across all the datasets and systems, we generally find that photos of individuals who are masculine presenting, older, of darker skin type, or have dim lighting are more …
One concern with the rise of large language models lies with their potential for significant harm, particularly from pretraining on biased, obscene, copyrighted, and private information. Emerging ethical approaches have attempted to filter pretraining material, but such approaches have been ad hoc and failed to take context into account. We offer an approach to filtering grounded in law, which has directly addressed the tradeoffs in filtering material. First, we gather and make available the Pile of Law, a ~256GB (and growing) dataset of open-source English-language legal and administrative data, covering court opinions, contracts, administrative rules, and legislative records. Pretraining on the Pile of Law may help with legal tasks that have the promise to improve access to justice. Second, we distill the legal norms that governments have developed to constrain the inclusion of toxic or private content into actionable lessons for researchers and discuss how our dataset reflects these norms. Third, we show how the Pile of Law offers researchers the opportunity to learn such filtering rules directly from the data, providing an exciting new research direction in model-based processing.
3D human pose and shape estimation (a.k.a. ``human mesh recovery'') has achieved substantial progress. Researchers mainly focus on the development of novel algorithms, while less attention has been paid to other critical factors involved. This could lead to less optimal baselines, hindering the fair and faithful evaluations of newly designed methodologies. To address this problem, this work presents the \textit{first} comprehensive benchmarking study from three under-explored perspectives beyond algorithms. \emph{1) Datasets.} An analysis on 31 datasets reveals the distinct impacts of data samples: datasets featuring critical attributes (\emph{i.e.} diverse poses, shapes, camera characteristics, backbone features) are more effective. Strategical selection and combination of high-quality datasets can yield a significant boost to the model performance. \emph{2) Backbones.} Experiments with 10 backbones, ranging from CNNs to transformers, show the knowledge learnt from a proximity task is readily transferable to human mesh recovery. \emph{3) Training strategies.} Proper augmentation techniques and loss designs are crucial. With the above findings, we achieve a PA-MPJPE of 47.3 (mm) on the 3DPW test set with a relatively simple model. More importantly, we provide strong baselines for fair comparisons of algorithms, and recommendations for building effective training configurations in the future. Codebase is available at \url{https://github.com/smplbody/hmr-benchmarks}.

There are already some text-based visual question answering (TextVQA) benchmarks for developing machine's ability to answer questions based on texts in images in recent years. However, models developed on these benchmarks cannot work effectively in many real-life scenarios (e.g. traffic monitoring, shopping ads and e-learning videos) where temporal reasoning ability is required. To this end, we propose a new task named Video Text Visual Question Answering (ViteVQA in short) that aims at answering questions by reasoning texts and visual information spatiotemporally in a given video. In particular, on the one hand, we build the first ViteVQA benchmark dataset named M4-ViteVQA --- the abbreviation of Multi-category Multi-frame Multi-resolution Multi-modal benchmark for ViteVQA, which contains 7,620 video clips of 9 categories (i.e., shopping, traveling, driving, vlog, sport, advertisement, movie, game and talking) and 3 kinds of resolutions (i.e., 720p, 1080p and 1176x664), and 25,123 question-answer pairs. On the other hand, we develop a baseline method named T5-ViteVQA for the ViteVQA task. T5-ViteVQA consists of five transformers. It first extracts optical character recognition (OCR) tokens, question features, and video representations via two OCR transformers, one language transformer and one video-language transformer, respectively. Then, a multimodal fusion transformer and an answer generation module are …

Combining information from multiple views is essential for discriminating similar objects. However, existing datasets for multi-view object classification have several limitations, such as synthetic and coarse-grained objects, no validation split for hyperparameter tuning, and a lack of view-level information quantity annotations for analyzing multi-view-based methods. To address this issue, this study proposes a new dataset, MVP-N, which contains 44 retail products, 16k real captured views with human-perceived information quantity annotations, and 9k multi-view sets. The fine-grained categorization of objects naturally generates multi-view label noise owing to the inter-class view similarity, allowing the study of learning from noisy labels in the multi-view case. Moreover, this study benchmarks four multi-view-based feature aggregation methods and twelve soft label methods on MVP-N. Experimental results show that MVP-N will be a valuable resource for facilitating the development of real-world multi-view object classification methods. The dataset and code are publicly available at https://github.com/SMNUResearch/MVP-N.

The COVID-19 pandemic continues to bring up various topics discussed or debated on social media. In order to explore the impact of pandemics on people's lives, it is crucial to understand the public's concerns and attitudes towards pandemic-related entities (e.g., drugs, vaccines) on social media. However, models trained on existing named entity recognition (NER) or targeted sentiment analysis (TSA) datasets have limited ability to understand COVID-19-related social media texts because these datasets are not designed or annotated from a medical perspective. In this paper, we release METS-CoV, a dataset containing medical entities and targeted sentiments from COVID-19 related tweets. METS-CoV contains 10,000 tweets with 7 types of entities, including 4 medical entity types (Disease, Drug, Symptom, and Vaccine) and 3 general entity types (Person, Location, and Organization). To further investigate tweet users' attitudes toward specific entities, 4 types of entities (Person, Organization, Drug, and Vaccine) are selected and annotated with user sentiments, resulting in a targeted sentiment dataset with 9,101 entities (in 5,278 tweets). To the best of our knowledge, METS-CoV is the first dataset to collect medical entities and corresponding sentiments of COVID-19 related tweets. We benchmark the performance of classical machine learning models and state-of-the-art deep learning models …

Existing benchmark datasets for recommender systems (RS) either are created at a small scale or involve very limited forms of user feedback. RS models evaluated on such datasets often lack practical values for large-scale real-world applications. In this paper, we describe Tenrec, a novel and publicly available data collection for RS that records various user feedback from four different recommendation scenarios. To be specific, Tenrec has the following five characteristics: (1) it is large-scale, containing around 5 million users and 140 million interactions; (2) it has not only positive user feedback, but also true negative feedback (vs. one-class recommendation); (3) it contains overlapped users and items across four different scenarios; (4) it contains various types of user positive feedback, in forms of clicking, liking, sharing, and following, etc; (5) it contains additional features beyond the user IDs and item IDs. We verify Tenrec on ten diverse recommendation tasks by running several classical baseline models per task. Tenrec has the potential to become a useful benchmark dataset for a majority of popular recommendation tasks. Our source codes and datasets will be included in supplementary materials.
Graph neural architecture search (GraphNAS) has recently aroused considerable attention in both academia and industry. However, two key challenges seriously hinder the further research of GraphNAS. First, since there is no consensus for the experimental setting, the empirical results in different research papers are often not comparable and even not reproducible, leading to unfair comparisons. Secondly, GraphNAS often needs extensive computations, which makes it highly inefficient and inaccessible to researchers without access to large-scale computation. To solve these challenges, we propose NAS-Bench-Graph, a tailored benchmark that supports unified, reproducible, and efficient evaluations for GraphNAS. Specifically, we construct a unified, expressive yet compact search space, covering 26,206 unique graph neural network (GNN) architectures and propose a principled evaluation protocol. To avoid unnecessary repetitive training, we have trained and evaluated all of these architectures on nine representative graph datasets, recording detailed metrics including train, validation, and test performance in each epoch, the latency, the number of parameters, etc. Based on our proposed benchmark, the performance of GNN architectures can be directly obtained by a look-up table without any further computation, which enables fair, fully reproducible, and efficient comparisons. To demonstrate its usage, we make in-depth analyses of our proposed NAS-Bench-Graph, revealing several …
There are over 300 sign languages in the world, many of which have very limited or no labelled sign-to-text datasets. To address low-resource data scenarios, self-supervised pretraining and multilingual finetuning have been shown to be effective in natural language and speech processing. In this work, we apply these ideas to sign language recognition.We make three contributions.- First, we release SignCorpus, a large pretraining dataset on sign languages comprising about 4.6K hours of signing data across 10 sign languages. SignCorpus is curated from sign language videos on the internet, filtered for data quality, and converted into sequences of pose keypoints thereby removing all personal identifiable information (PII).- Second, we release Sign2Vec, a graph-based model with 5.2M parameters that is pretrained on SignCorpus. We envisage Sign2Vec as a multilingual large-scale pretrained model which can be fine-tuned for various sign recognition tasks across languages.- Third, we create MultiSign-ISLR -- a multilingual and label-aligned dataset of sequences of pose keypoints from 11 labelled datasets across 7 sign languages, and MultiSign-FS -- a new finger-spelling training and test set across 7 languages. On these datasets, we fine-tune Sign2Vec to create multilingual isolated sign recognition models. With experiments on multiple benchmarks, we show that pretraining and …
Wasserstein Generative Adversarial Networks (WGANs) are the popular generative models built on the theory of Optimal Transport (OT) and the Kantorovich duality. Despite the success of WGANs, it is still unclear how well the underlying OT dual solvers approximate the OT cost (Wasserstein-1 distance, W1) and the OT gradient needed to update the generator. In this paper, we address these questions. We construct 1-Lipschitz functions and use them to build ray monotone transport plans. This strategy yields pairs of continuous benchmark distributions with the analytically known OT plan, OT cost and OT gradient in high-dimensional spaces such as spaces of images. We thoroughly evaluate popular WGAN dual form solvers (gradient penalty, spectral normalization, entropic regularization, etc.) using these benchmark pairs. Even though these solvers perform well in WGANs, none of them faithfully compute W1 in high dimensions. Nevertheless, many provide a meaningful approximation of the OT gradient. These observations suggest that these solvers should not be treated as good estimators of W1 but to some extent they indeed can be used in variational problems requiring the minimization of W1.
Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat unknown and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of …
Backdoor learning is an emerging and vital topic for studying deep neural networks' vulnerability (DNNs). Many pioneering backdoor attack and defense methods are being proposed, successively or concurrently, in the status of a rapid arms race. However, we find that the evaluations of new methods are often unthorough to verify their claims and accurate performance, mainly due to the rapid development, diverse settings, and the difficulties of implementation and reproducibility. Without thorough evaluations and comparisons, it is not easy to track the current progress and design the future development roadmap of the literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning called BackdoorBench. It consists of an extensible modular-based codebase (currently including implementations of 8 state-of-the-art (SOTA) attacks and 9 SOTA defense algorithms) and a standardized protocol of complete backdoor learning. We also provide comprehensive evaluations of every pair of 8 attacks against 9 defenses, with 5 poisoning ratios, based on 5 models and 4 datasets, thus 8,000 pairs of evaluations in total. We present abundant analysis from different perspectives about these 8,000 evaluations, studying the effects of different factors in backdoor learning. All codes and evaluations of BackdoorBench are publicly available at https://backdoorbench.github.io.
The lack of publicly available high-quality and accurately labeled datasets has long been a major bottleneck for singing voice synthesis (SVS). To tackle this problem, we present M4Singer, a free-to-use Multi-style, Multi-singer Mandarin singing collection with elaborately annotated Musical scores as well as its benchmarks. Specifically, 1) we construct and release a large high-quality Chinese singing voice corpus, which is recorded by 20 professional singers, covering 700 Chinese pop songs as well as all the four SATB types (i.e., soprano, alto, tenor, and bass); 2) we take extensive efforts to manually compose the musical scores for each recorded song, which are necessary to the study of the prosody modeling for SVS. 3) To facilitate the use and demonstrate the quality of M4Singer, we conduct four different benchmark experiments: score-based SVS, controllable singing voice (CSV), singing voice conversion (SVC) and automatic music transcription (AMT).

Animal pose estimation and tracking (APT) is a fundamental task for detecting and tracking animal keypoints from a sequence of video frames. Previous animal-related datasets focus either on animal tracking or single-frame animal pose estimation, and never on both aspects. The lack of APT datasets hinders the development and evaluation of video-based animal pose estimation and tracking methods, limiting the applications in real world, e.g., understanding animal behavior in wildlife conservation. To fill this gap, we make the first step and propose APT-36K, i.e., the first large-scale benchmark for animal pose estimation and tracking. Specifically, APT-36K consists of 2,400 video clips collected and filtered from 30 animal species with 15 frames for each video, resulting in 36,000 frames in total. After manual annotation and careful double-check, high-quality keypoint and tracking annotations are provided for all the animal instances. Based on APT-36K, we benchmark several representative models on the following three tracks: (1) supervised animal pose estimation on a single frame under intra- and inter-domain transfer learning settings, (2) inter-species domain generalization test for unseen animals, and (3) animal pose estimation with animal tracking. Based on the experimental results, we gain some empirical insights and show that APT-36K provides a useful …

Twitter bot detection has become an increasingly important task to combat misinformation, facilitate social media moderation, and preserve the integrity of the online discourse. State-of-the-art bot detection methods generally leverage the graph structure of the Twitter network, and they exhibit promising performance when confronting novel Twitter bots that traditional methods fail to detect. However, very few of the existing Twitter bot detection datasets are graph-based, and even these few graph-based datasets suffer from limited dataset scale, incomplete graph structure, as well as low annotation quality. In fact, the lack of a large-scale graph-based Twitter bot detection benchmark that addresses these issues has seriously hindered the development and evaluation of novel graph-based bot detection approaches. In this paper, we propose TwiBot-22, a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date, provides diversified entities and relations on the Twitter network, and has considerably better annotation quality than existing datasets. In addition, we re-implement 35 representative Twitter bot detection baselines and evaluate them on 9 datasets, including TwiBot-22, to promote a fair comparison of model performance and a holistic understanding of research progress. To facilitate further research, we consolidate all implemented codes and datasets into the TwiBot-22 evaluation …
Large, diachronic datasets of political discourse are hard to come across, especially for resource-lean languages such as Greek. In this paper, we introduce a curated dataset of the Greek Parliament Proceedings that extends chronologically from 1989 up to 2020. It consists of more than 1 million speeches with extensive meta-data, extracted from 5,355 parliamentary sitting record files. We explain how it was constructed and the challenges that had to be overcome. The dataset can be used for both computational linguistics and political analysis---ideally, combining the two. We present such an application, showing (i) how the dataset can be used to study the change of word usage through time, (ii) between significant historical events and political parties, (iii) by evaluating and employing algorithms for detecting semantic shifts.

Social media platforms were conceived to act as online town squares' where people could get together, share information and communicate with each other peacefully. However, harmful content borne out of bad actors are constantly plaguing these platforms slowly converting them intomosh pits' where the bad actors take the liberty to extensively abuse various marginalised groups. Accurate and timely detection of abusive content on social media platforms is therefore very important for facilitating safe interactions between users. However, due to the small scale and sparse linguistic coverage of Indic abusive speech datasets, development of such algorithms for Indic social media users (one-sixth of global population) is severely impeded.To facilitate and encourage research in this important direction, we contribute for the first time MACD - a large-scale (150K), human-annotated, multilingual (5 languages), balanced (49\% abusive content) and diverse (70K users) abuse detection dataset of user comments, sourced from a popular social media platform - ShareChat. We also release AbuseXLMR, an abusive content detection model pretrained on large number of social media comments in 15+ Indic languages which outperforms XLM-R and MuRIL on multiple Indic datasets. Along with the annotations, we also release the mapping between comment, post and user id's to …
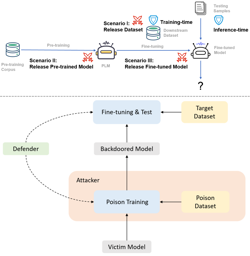
Textual backdoor attacks are a kind of practical threat to NLP systems. By injecting a backdoor in the training phase, the adversary could control model predictions via predefined triggers. As various attack and defense models have been proposed, it is of great significance to perform rigorous evaluations. However, we highlight two issues in previous backdoor learning evaluations: (1) The differences between real-world scenarios (e.g. releasing poisoned datasets or models) are neglected, and we argue that each scenario has its own constraints and concerns, thus requires specific evaluation protocols; (2) The evaluation metrics only consider whether the attacks could flip the models' predictions on poisoned samples and retain performances on benign samples, but ignore that poisoned samples should also be stealthy and semantic-preserving. To address these issues, we categorize existing works into three practical scenarios in which attackers release datasets, pre-trained models, and fine-tuned models respectively, then discuss their unique evaluation methodologies. On metrics, to completely evaluate poisoned samples, we use grammar error increase and perplexity difference for stealthiness, along with text similarity for validity. After formalizing the frameworks, we develop an open-source toolkit OpenBackdoor to foster the implementations and evaluations of textual backdoor learning. With this toolkit, we perform extensive …

Vision-Language Pre-training (VLP) has been shown to be an efficient method to improve the performance of models on different vision-and-language downstream tasks. Substantial studies have shown that neural networks may be able to learn some general rules about language and visual concepts from a large-scale weakly labeled image-text dataset. However, most of the public cross-modal datasets that contain more than 100M image-text pairs are in English; there is a lack of available large-scale and high-quality Chinese VLP datasets. In this work, we propose a new framework for automatic dataset acquisition and cleaning with which we construct a new large-scale and high-quality cross-modal dataset named as TaiSu, containing 166 million images and 219 million Chinese captions. Compared with the recently released Wukong dataset, our dataset is achieved with much stricter restrictions on the semantic correlation of image-text pairs. We also propose to combine texts collected from the web with texts generated by a pre-trained image-captioning model. To the best of our knowledge, TaiSu is currently the largest publicly accessible Chinese cross-modal dataset. Furthermore, we test our dataset on several vision-language downstream tasks. TaiSu outperforms BriVL by a large margin on the zero-shot image-text retrieval task and zero-shot image classification task. TaiSu …

Graph Anomaly Detection (GAD) has recently become a hot research spot due to its practicability and theoretical value. Since GAD emphasizes the application and the rarity of anomalous samples, enriching the varieties of its datasets is fundamental. Thus, this paper present DGraph, a real-world dynamic graph in the finance domain. DGraph overcomes many limitations of current GAD datasets. It contains about 3M nodes, 4M dynamic edges, and 1M ground-truth nodes. We provide a comprehensive observation of DGraph, revealing that anomalous nodes and normal nodes generally have different structures, neighbor distribution, and temporal dynamics. Moreover, it suggests that 2M background nodes are also essential for detecting fraudsters. Furthermore, we conduct extensive experiments on DGraph. Observation and experiments demonstrate that DGraph is propulsive to advance GAD research and enable in-depth exploration of anomalous nodes.

In order to diagnostically analyze and improve the capability of pretrained language models (PLMs) in text generation, we propose TGEA 2.0, to date the largest dataset built on machine-authored texts by PLMs with fine-grained semantic annotations on a wide variety of pathological generation errors. We collect 170K nominal, phrasal and sentential prompts from 6M natural sentences in 3 domains. These prompts are fed into 4 generative PLMs with their best decoding strategy to generate paragraphs. 195,629 sentences are extracted from these generated paragraphs for manual annotation, where 36K erroneous sentences are detected, 42K erroneous spans are located and categorized into an error type defined in a two-level error taxonomy. We define a \textbf{Mi}nimal \textbf{S}et of \textbf{E}rror-related \textbf{W}ords (MiSEW) for each erroneous span, which not only provides error-associated words but also rationalizes the reasoning behind the error. Quality control with a pre-annotation and feedback loop is performed before and during the entire annotation process. With the diagnostically annotated dataset, we propose 5 diagnosis benchmark tasks (i.e., erroneous text detection, MiSEW extraction, erroneous span location and correction together with error type classification) and 2 pathology mitigation benchmark tasks (pairwise comparison and word prediction). Experiment results on these benchmark tasks demonstrate that TGEA …

Achieving human-level dexterity is an important open problem in robotics. However, tasks of dexterous hand manipulation even at the baby level are challenging to solve through reinforcement learning (RL). The difficulty lies in the high degrees of freedom and the required cooperation among heterogeneous agents (e.g., joints of fingers). In this study, we propose the Bimanual Dexterous Hands Benchmark (Bi-DexHands), a simulator that involves two dexterous hands with tens of bimanual manipulation tasks and thousands of target objects. Tasks in Bi-DexHands are first designed to match human-level motor skills according to literature in cognitive science, and then are built in Issac Gym; this enables highly efficient RL trainings, reaching 30,000+ FPS by only one single NVIDIA RTX 3090. We provide a comprehensive benchmark for popular RL algorithms under different settings; this includes multi-agent RL, offline RL, multi-task RL, and meta RL. Our results show that PPO type on-policy algorithms can learn to solve simple manipulation tasks that are equivalent up to 48-month human baby (e.g., catching a flying object, opening a bottle), while multi-agent RL can further help to learn manipulations that require skilled bimanual cooperation (e.g., lifting a pot, stacking blocks). Despite the success on each individual task, when …
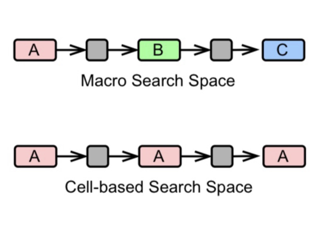
Neural architecture search (NAS) has been successfully used to design numerous high-performance neural networks. However, NAS is typically compute-intensive, so most existing approaches restrict the search to decide the operations and topological structure of a single block only, then the same block is stacked repeatedly to form an end-to-end model. Although such an approach reduces the size of search space, recent studies show that a macro search space, which allows blocks in a model to be different, can lead to better performance. To provide a systematic study of the performance of NAS algorithms on a macro search space, we release Blox – a benchmark that consists of 91k unique models trained on the CIFAR-100 dataset. The dataset also includes runtime measurements of all the models on a diverse set of hardware platforms. We perform extensive experiments to compare existing algorithms that are well studied on cell-based search spaces, with the emerging blockwise approaches that aim to make NAS scalable to much larger macro search spaces. The Blox benchmark and code are available at https://github.com/SamsungLabs/blox.