Poster
CommonScenes: Generating Commonsense 3D Indoor Scenes with Scene Graph Diffusion
Guangyao Zhai · Evin Pınar Örnek · Shun-Cheng Wu · Yan Di · Federico Tombari · Nassir Navab · Benjamin Busam
Great Hall & Hall B1+B2 (level 1) #217
{kind=link}
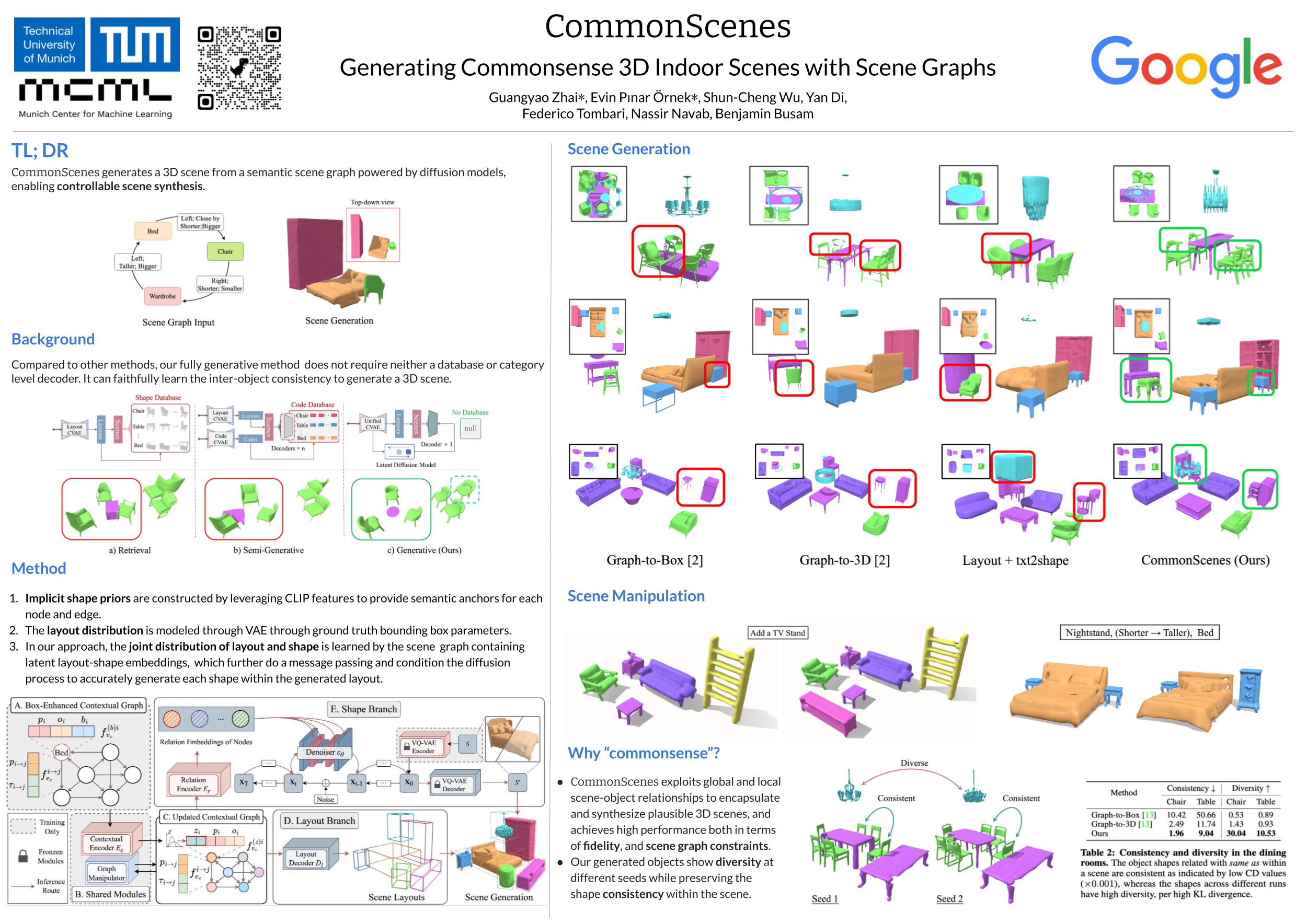
Controllable scene synthesis aims to create interactive environments for numerous industrial use cases. Scene graphs provide a highly suitable interface to facilitate these applications by abstracting the scene context in a compact manner. Existing methods, reliant on retrieval from extensive databases or pre-trained shape embeddings, often overlook scene-object and object-object relationships, leading to inconsistent results due to their limited generation capacity. To address this issue, we present CommonScenes, a fully generative model that converts scene graphs into corresponding controllable 3D scenes, which are semantically realistic and conform to commonsense. Our pipeline consists of two branches, one predicting the overall scene layout via a variational auto-encoder and the other generating compatible shapes via latent diffusion, capturing global scene-object and local inter-object relationships in the scene graph while preserving shape diversity. The generated scenes can be manipulated by editing the input scene graph and sampling the noise in the diffusion model. Due to the lack of a scene graph dataset offering high-quality object-level meshes with relations, we also construct SG-FRONT, enriching the off-the-shelf indoor dataset 3D-FRONT with additional scene graph labels. Extensive experiments are conducted on SG-FRONT, where CommonScenes shows clear advantages over other methods regarding generation consistency, quality, and diversity. Codes and the dataset are available on the website.