Poster
Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
Zhang-Wei Hong · Aviral Kumar · Sathwik Karnik · Abhishek Bhandwaldar · Akash Srivastava · Joni Pajarinen · Romain Laroche · Abhishek Gupta · Pulkit Agrawal
Great Hall & Hall B1+B2 (level 1) #1908
{kind=link}
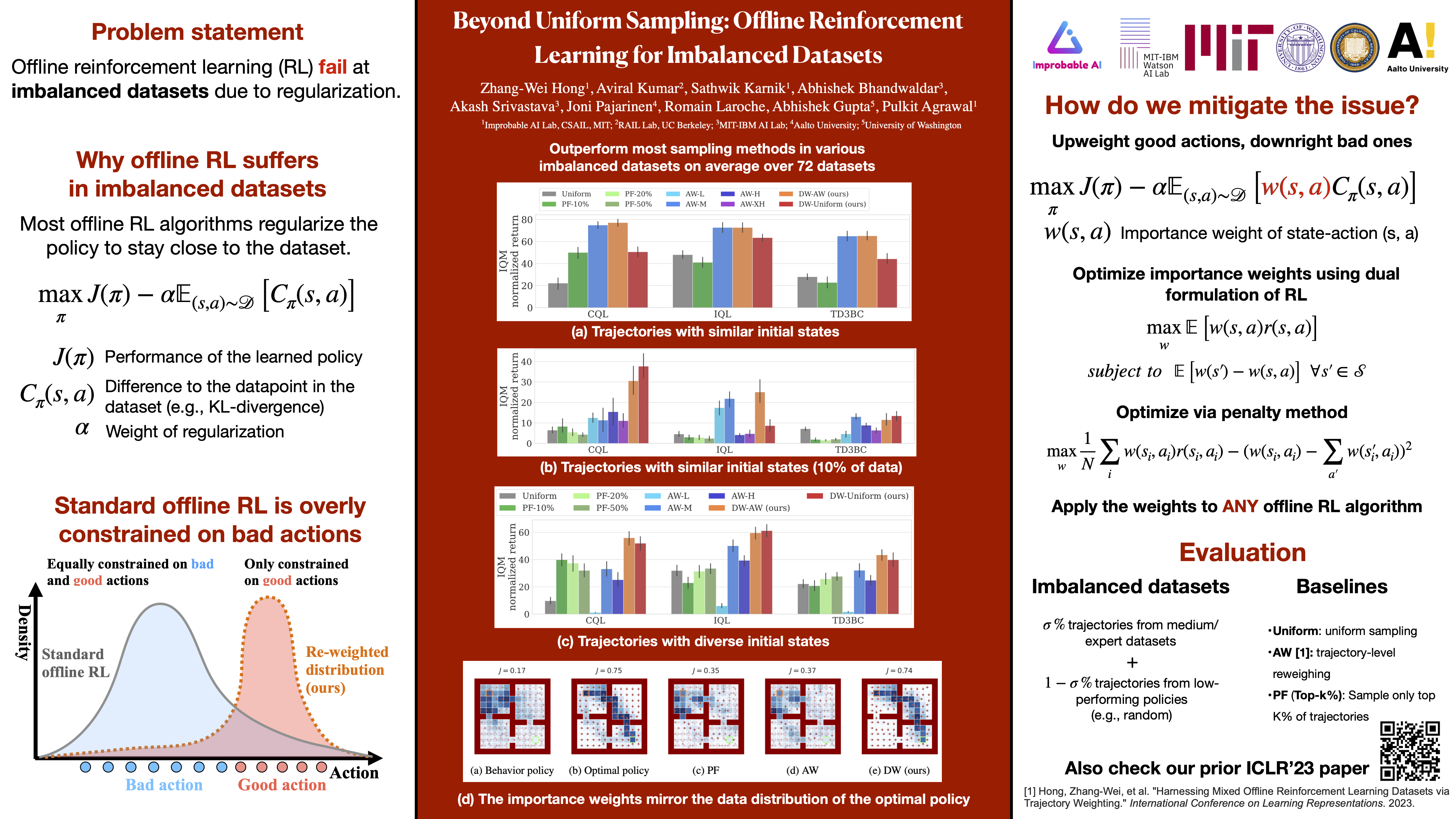
Offline reinforcement learning (RL) enables learning a decision-making policy without interaction with the environment. This makes it particularly beneficial in situations where such interactions are costly. However, a known challenge for offline RL algorithms is the distributional mismatch between the state-action distributions of the learned policy and the dataset, which can significantly impact performance. State-of-the-art algorithms address it by constraining the policy to align with the state-action pairs in the dataset. However, this strategy struggles on datasets that predominantly consist of trajectories collected by low-performing policies and only a few trajectories from high-performing ones. Indeed, the constraint to align with the data leads the policy to imitate low-performing behaviors predominating the dataset. Our key insight to address this issue is to constrain the policy to the policy that collected the good parts of the dataset rather than all data. To this end, we optimize the importance sampling weights to emulate sampling data from a data distribution generated by a nearly optimal policy. Our method exhibits considerable performance gains (up to five times better) over the existing approaches in state-of-the-art offline RL algorithms over 72 imbalanced datasets with varying types of imbalance.