Poster
Efficient Symbolic Policy Learning with Differentiable Symbolic Expression
Jiaming Guo · Rui Zhang · Shaohui Peng · Qi Yi · Xing Hu · Ruizhi Chen · Zidong Du · xishan zhang · Ling Li · Qi Guo · Yunji Chen
Great Hall & Hall B1+B2 (level 1) #1406
{kind=link}
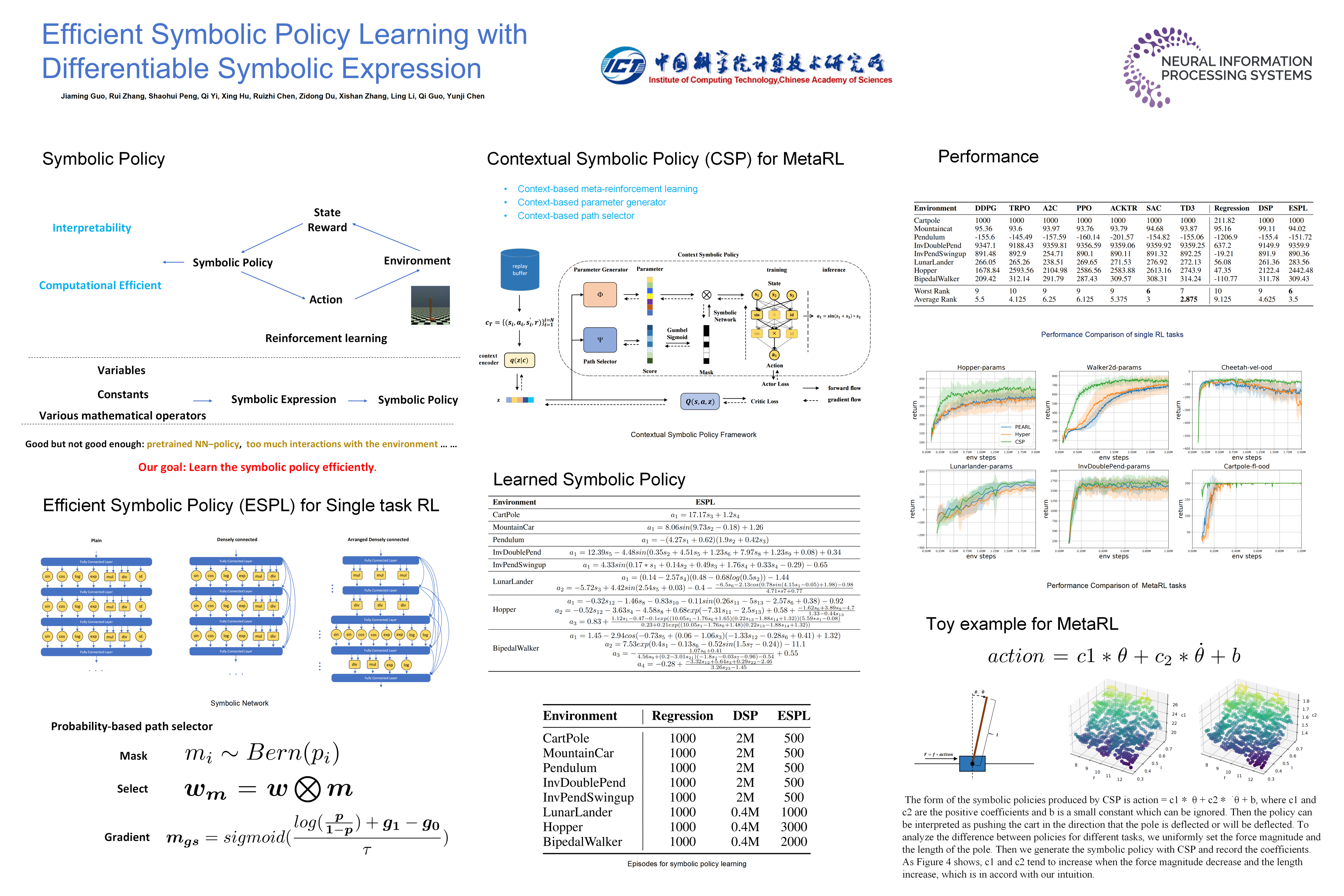
Deep reinforcement learning (DRL) has led to a wide range of advances in sequential decision-making tasks. However, the complexity of neural network policies makes it difficult to understand and deploy with limited computational resources. Currently, employing compact symbolic expressions as symbolic policies is a promising strategy to obtain simple and interpretable policies. Previous symbolic policy methods usually involve complex training processes and pre-trained neural network policies, which are inefficient and limit the application of symbolic policies. In this paper, we propose an efficient gradient-based learning method named Efficient Symbolic Policy Learning (ESPL) that learns the symbolic policy from scratch in an end-to-end way. We introduce a symbolic network as the search space and employ a path selector to find the compact symbolic policy. By doing so we represent the policy with a differentiable symbolic expression and train it in an off-policy manner which further improves the efficiency. In addition, in contrast with previous symbolic policies which only work in single-task RL because of complexity, we expand ESPL on meta-RL to generate symbolic policies for unseen tasks. Experimentally, we show that our approach generates symbolic policies with higher performance and greatly improves data efficiency for single-task RL. In meta-RL, we demonstrate that compared with neural network policies the proposed symbolic policy achieves higher performance and efficiency and shows the potential to be interpretable.