Poster
in
Workshop: Agent Learning in Open-Endedness Workshop
DOGE: Domain Reweighting with Generalization Estimation
Simin Fan · Matteo Pagliardini · Martin Jaggi
Keywords: [ generalization ] [ pretraining ] [ language model ]
{kind=link}
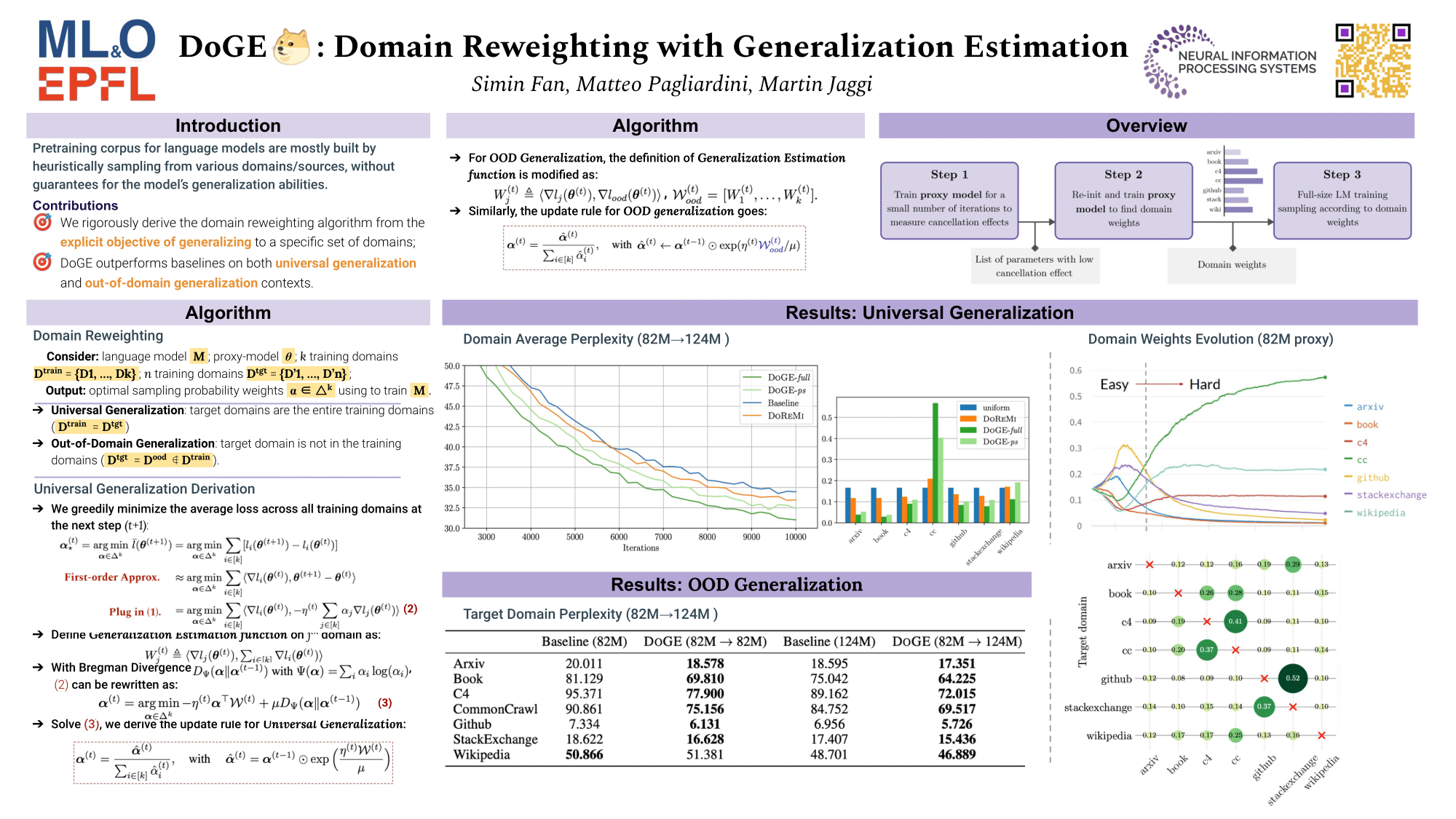
The coverage and composition of the pretraining data corpus significantly impacts the generalization ability of large language models. Conventionally, the pretraining corpus is composed of various source domains (e.g. CommonCrawl, Wikipedia, Github etc.) according to certain sampling probabilities (domain weights). However, current methods lack a principled way to optimize domain weights for ultimate goal for generalization. We propose \textsc{DO}main reweighting with \textsc{G}eneralization \textsc{E}stimation (DoGE), where we reweigh the sampling probability from each domain based on its contribution to the final generalization objective assessed by a gradient-based generalization estimation function. First, we train a small-scale proxy model with a min-max optimization to obtain the reweighted domain weights. At each step, the domain weights are updated to maximize the overall generalization gain by mirror descent. Finally we use the obtained domain weights to train a larger scale full-size language model. On SlimPajama-6B dataset, with universal generalization objective, DoGE achieves better average perplexity and zero-shot reasoning accuracy. On out-of-domain generalization tasks, DoGE reduces perplexity on the target domain by a large margin. We further apply a parameter-selection scheme which improves the efficiency of generalization estimation.