Poster
in
Workshop: Deep Generative Models for Health
Synthetic Data: Can We Trust Statistical Estimators?
Alexander Decruyenaere · Paloma Rabaey · Christiaan Polet · Johan Decruyenaere · Stijn Vansteelandt · Thomas Demeester · Heidelinde Dehaene
{kind=link}
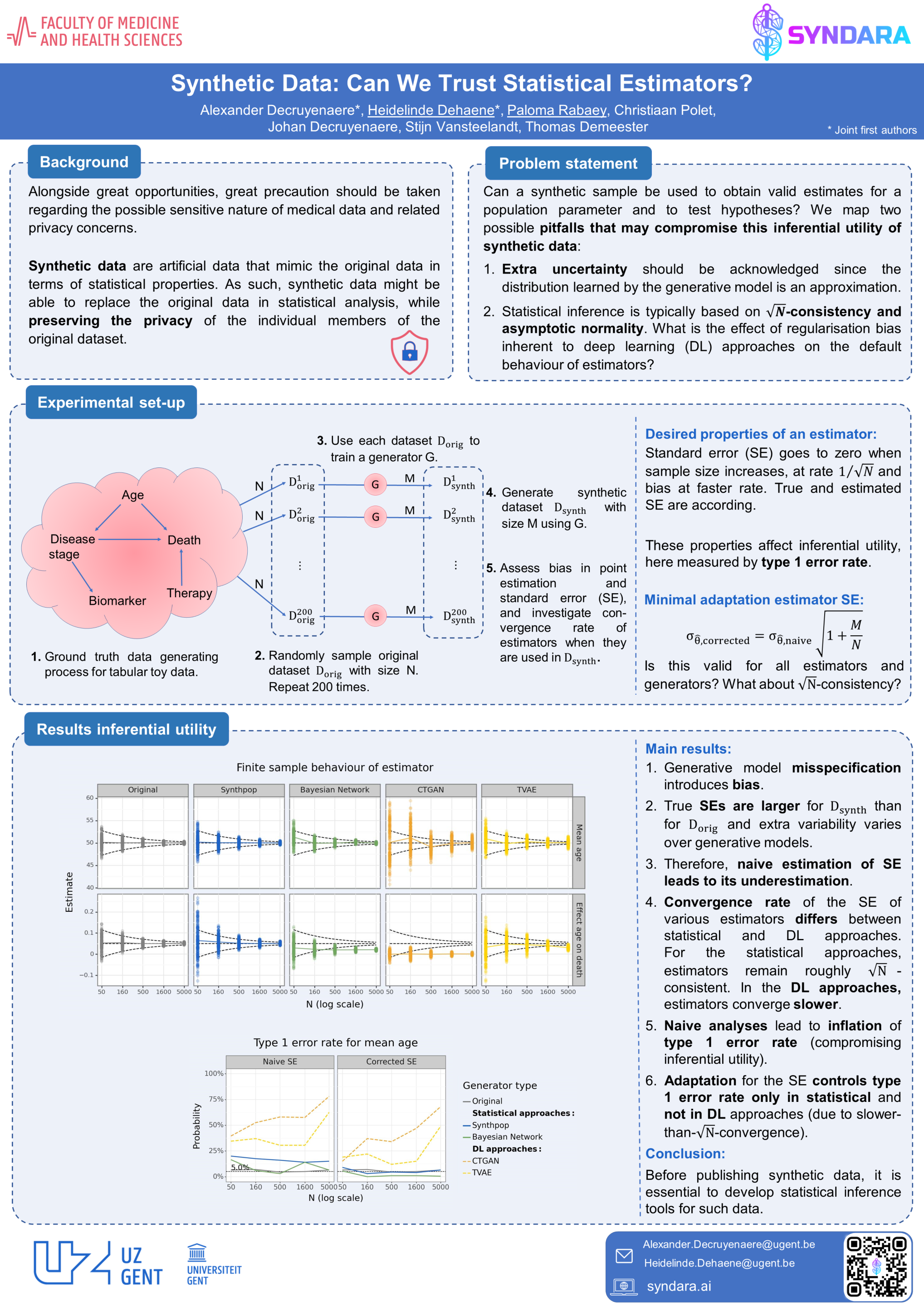
The increasing interest in data sharing makes synthetic data particularly appealing. However, the analysis of synthetic data raises a unique set of methodological challenges. In this work, we highlight the importance of inferential utility and provide empirical evidence that naive inference from synthetic data (that handles these as if they were really observed) is not appropriate, as the rate of false-positive findings (type I error) will be unacceptably high, even when the estimates are unbiased, due to underestimation of the true standard error. This is even more problematic for deep generative models. Valid inference from synthetic data will necessitate the construction of valid standard errors, to which our work contributes.