Poster
in
Workshop: OPT 2023: Optimization for Machine Learning
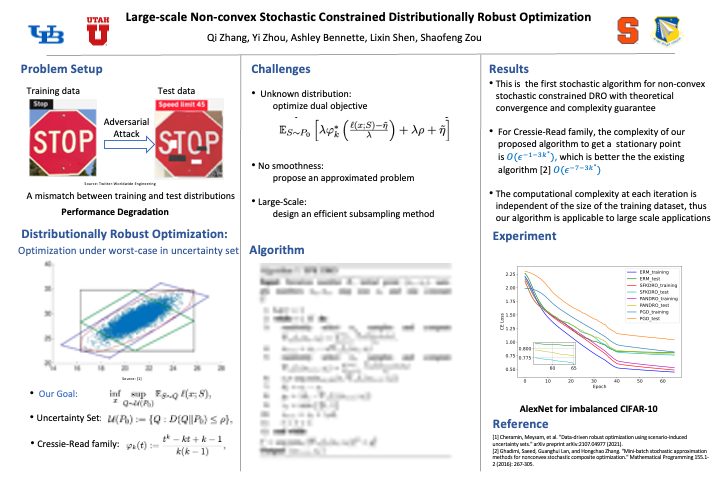
Large-scale Non-convex Stochastic Constrained Distributionally Robust Optimization
Qi Zhang · Shaofeng Zou · Yi Zhou · Lixin Shen · Ashley Prater-Bennette
{kind=link}
Abstract:
Distributionally robust optimization (DRO) is a powerful framework for training robust models against data distribution shifts. This paper focuses on constrained DRO, which has an explicit characterization of the robustness level. Existing studies on constrained DRO mostly focus on convex loss function, and exclude the practical and challenging case with non-convex loss function, e.g., neural network. This paper develops a stochastic algorithm and its performance analysis for non-convex constrained DRO. The computational complexity of our stochastic algorithm at each iteration is independent of the overall dataset size, and thus is suitable for large-scale applications. We focus on the general Cressie-Read family divergence defined uncertainty set which includes $\chi^2$-divergences as a special case. We prove that our algorithm finds an $\epsilon$-stationary point with an improved computational complexity than existing methods. Our method also applies to the smoothed conditional value at risk (CVaR) DRO.
Chat is not available.