Poster
in
Workshop: I Can’t Believe It’s Not Better: Understanding Deep Learning Through Empirical Falsification
How many trained neural networks are needed for influence estimation in modern deep learning?
Sasha (Alexandre) Doubov · Tianshi Cao · David Acuna · Sanja Fidler
{kind=link}
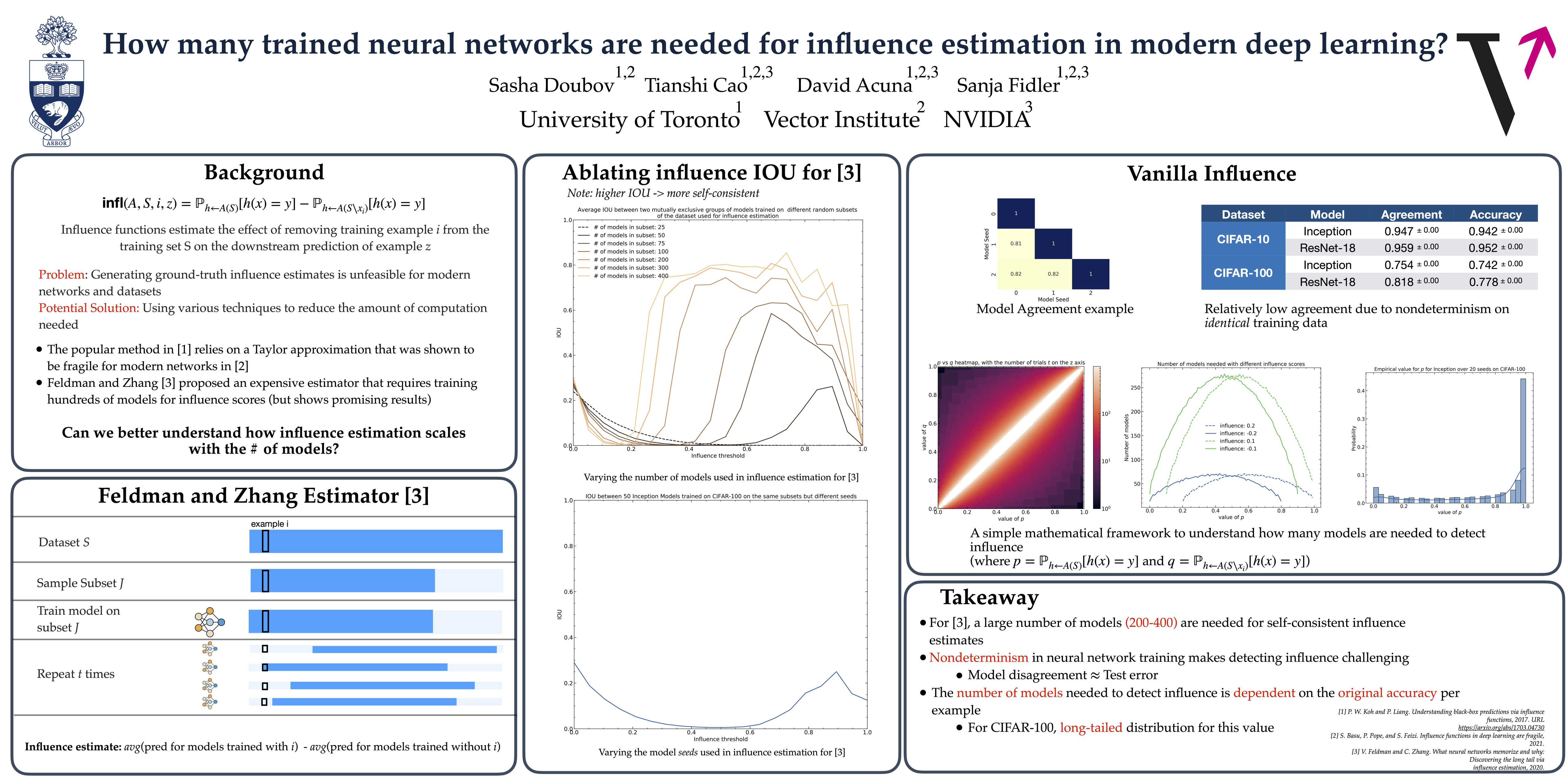
Influence estimation attempts to estimate the effect of removing a training example on downstream predictions. Prior work has shown that a first-order approximation to estimate influence does not agree with the ground-truth of re-training or fine-tuning without a training example. Recently, Feldman and Zhang [2020] created an influence estimator that provides meaningful influence estimates but requires training thousands of models on large subsets of a dataset. In this work, we explore how the method in Feldman and Zhang [2020] scales with the number of trained models. We also show empirical and analytical results in the standard influence estimation setting that provide intuitions about the role of nondeterminism in neural network training and how the accuracy of test predictions affects the number of models needed to detect an influential training example. We ultimately find that a large amount of models are needed for influence estimation, though the exact number is hard to quantify due to training nondeterminism and depends on test example difficulty, which varies between tasks.