Poster
in
Workshop: Deep Reinforcement Learning Workshop
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
Mhairi Dunion · Trevor McInroe · Kevin Sebastian Luck · Josiah Hanna · Stefano Albrecht
{kind=link}
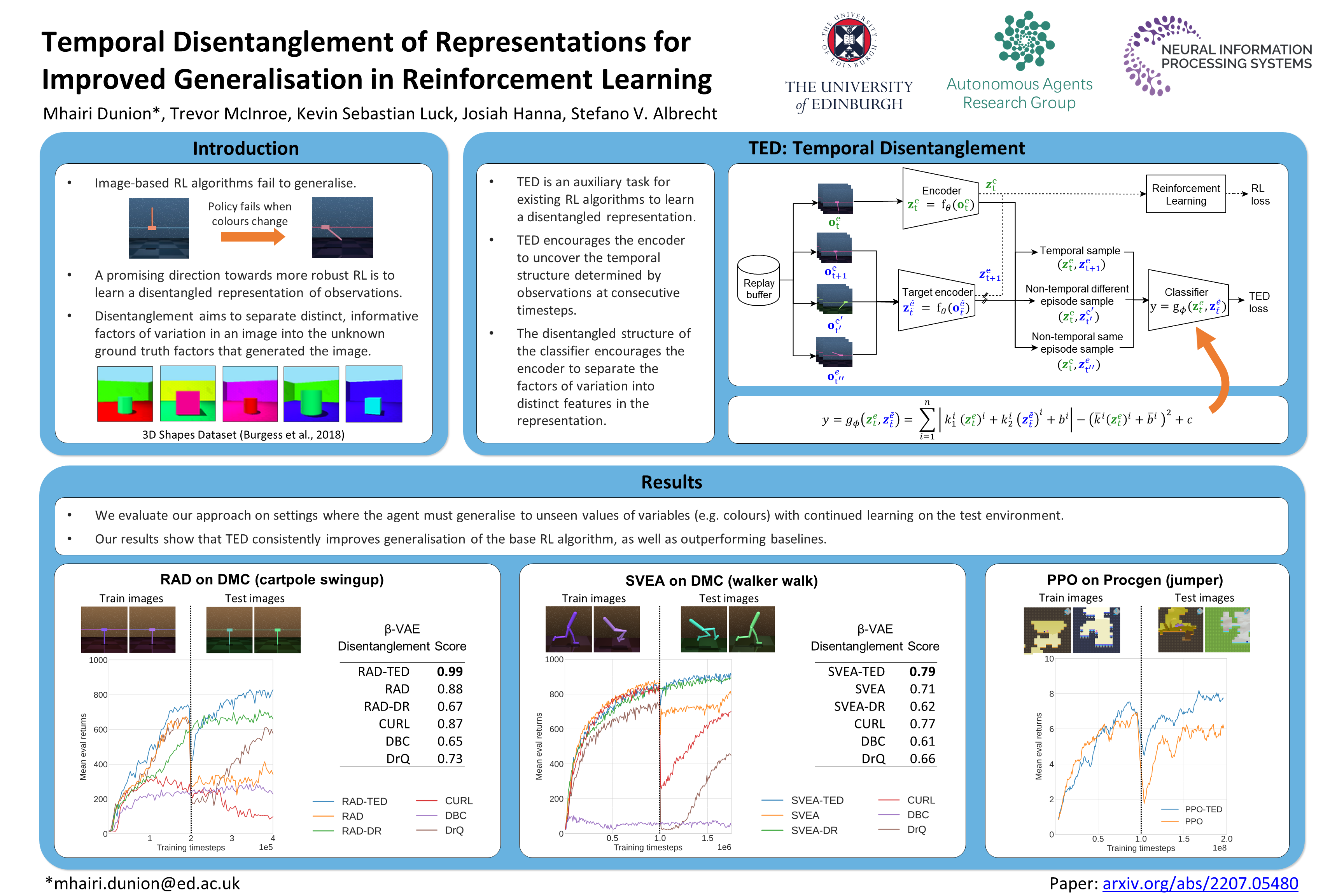
Reinforcement Learning (RL) agents are often unable to generalise well to environment variations in the state space that were not observed during training. This issue is especially problematic for image-based RL, where a change in just one variable, such as the background colour, can change many pixels in the image, which can lead to drastic changes in the agent's latent representation of the image, causing the learned policy to fail. To learn more robust representations, we introduce TEmporal Disentanglement (TED), a self-supervised auxiliary task that leads to disentangled image representations exploiting the sequential nature of RL observations. We find empirically that RL algorithms utilising TED as an auxiliary task adapt more quickly to changes in environment variables with continued training compared to state-of-the-art representation learning methods. Since TED enforces a disentangled structure of the representation, we also find that policies trained with TED generalise better to unseen values of variables irrelevant to the task (e.g.\ background colour) as well as unseen values of variables that affect the optimal policy (e.g.\ goal positions).