Poster
in
Workshop: Deep Reinforcement Learning Workshop
On The Fragility of Learned Reward Functions
Lev McKinney · Yawen Duan · Adam Gleave · David Krueger
{kind=link}
Abstract:
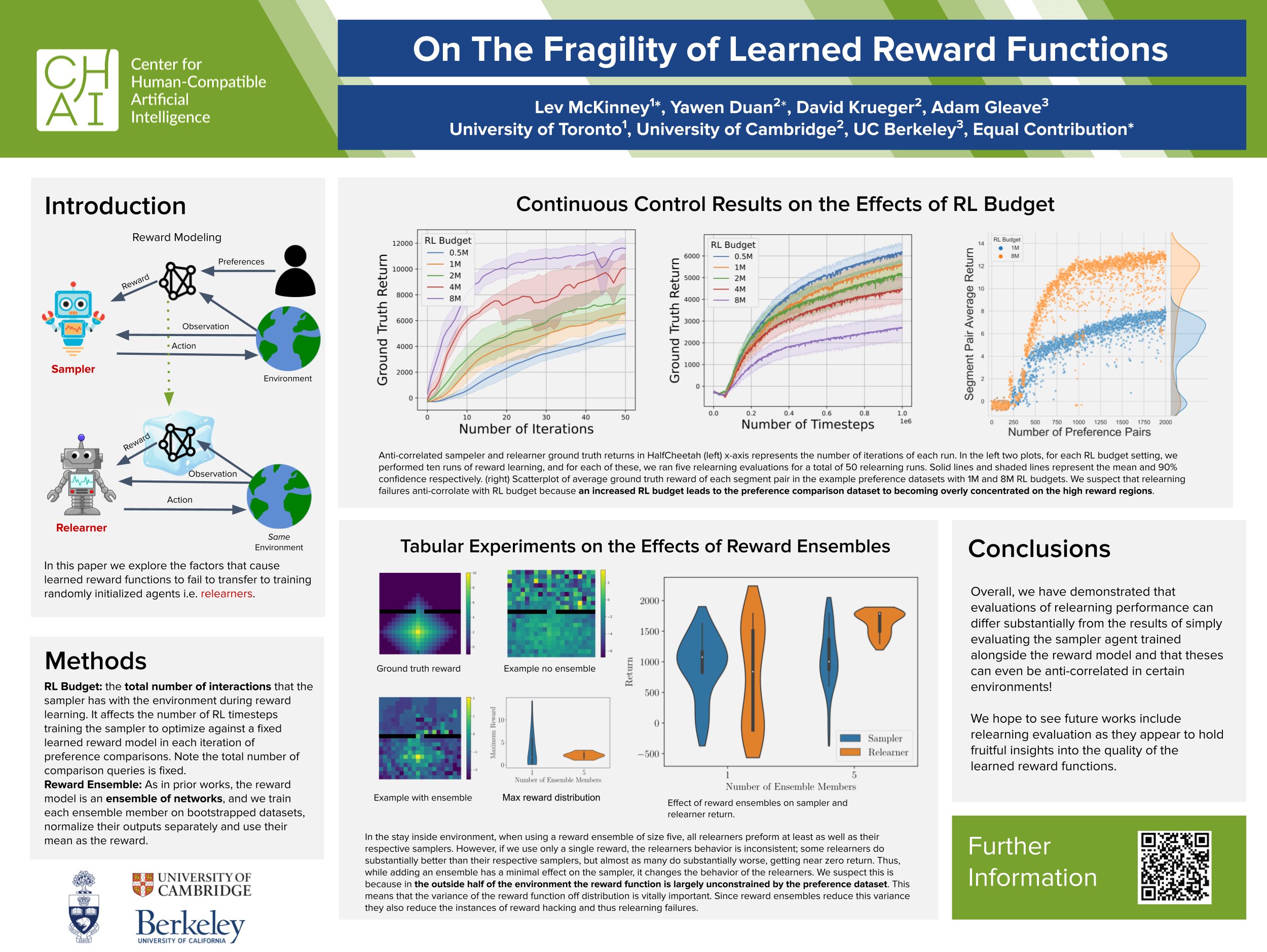
Reward functions are notoriously difficult to specify, especially for tasks with complex goals. Reward learning approaches attempt to infer reward functions from human feedback and preferences. Prior works on reward learning mainly focus on achieving high final performance for agents trained alongside the reward function. However, many of these works fail to investigate whether the resulting learned reward model accurately captures the intended behavior. In this work, we focus on the $\textit{relearning}$ failures of learned reward models. We demonstrate that when they are reused to train randomly initialized policies by designing experiments on both tabular and continuous control environments. We found that the severity of relearning failure might be sensitive to changes in reward model design and the trajectory dataset. Finally, we discussed the potential limitations of our methods and emphases the need for more retraining-based evaluations in the literature.
Chat is not available.