Poster
in
Workshop: NeurIPS 2022 Workshop on Meta-Learning
Learning to Prioritize Planning Updates in Model-based Reinforcement Learning
Brad Burega · John Martin · Michael Bowling
{kind=link}
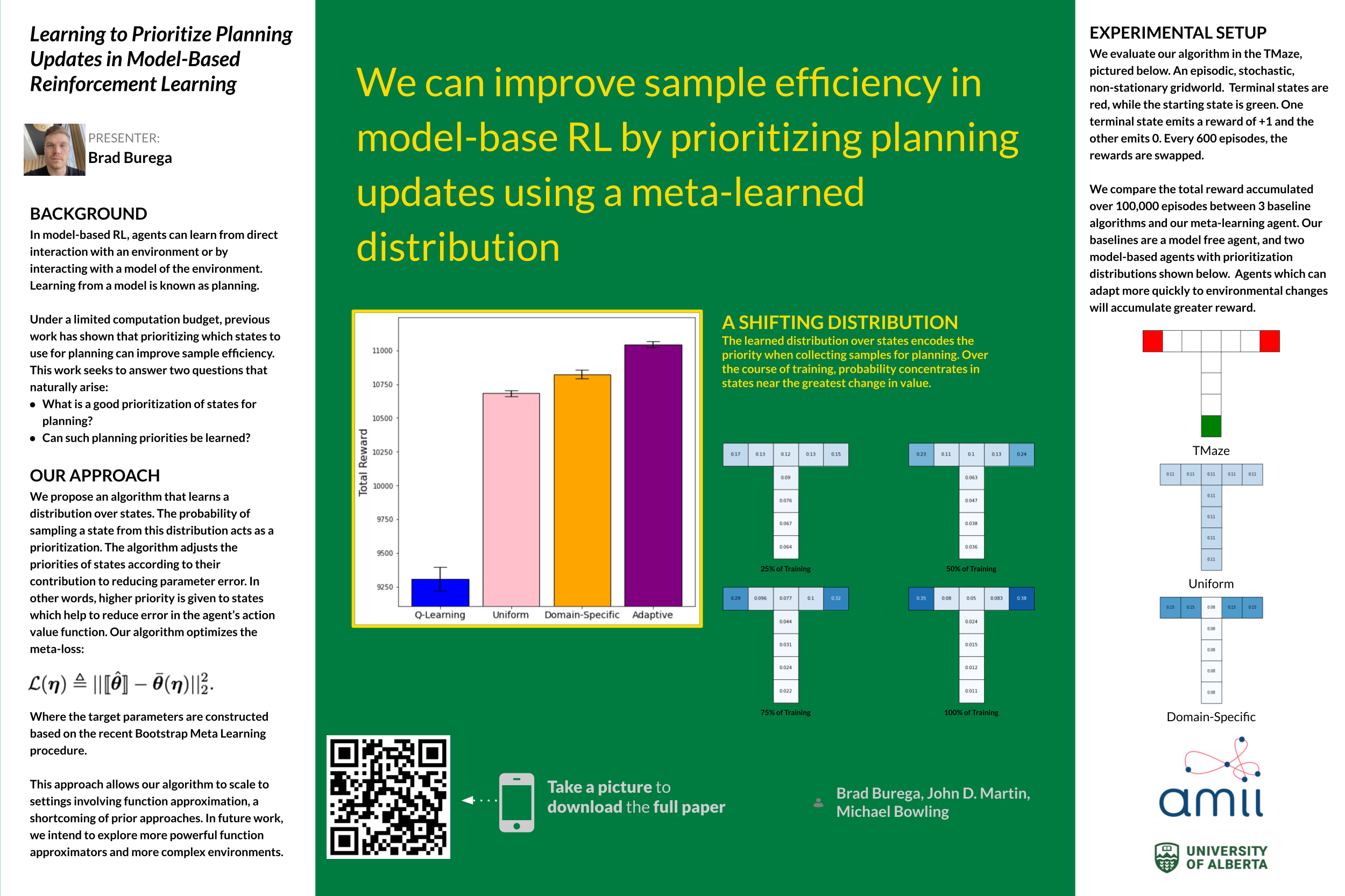
Prioritizing the states and actions from which policy improvement is performed can improve the sample efficiency of model-based reinforcement learning systems. Although much is already known about prioritizing planning updates, more needs to be understood to operationalize these ideas in complex settings that involve non-stationary and stochastic transition dynamics, large numbers of states, and scalable function approximation architectures. Our paper presents an online meta-learning algorithm to address these needs. The algorithm finds distributions that encode priority in their probability mass. The paper evaluates the algorithm in a domain with a changing goal and with a fixed, generative transition model. Results show that prioritizing planning updates from samples of the meta-learned distribution significantly improves sample efficiency over fixed baseline distributions. Additionally, they point to a number of interesting opportunities for future research.