[2nd] Poster Session
in
Workshop: Vision Transformers: Theory and applications
PatchRot: A Self-Supervised Technique for Training Vision Transformers
Sachin Chhabra · Prabal Bijoy Dutta · Hemanth Venkateswara · baoxin Li
{kind=link}
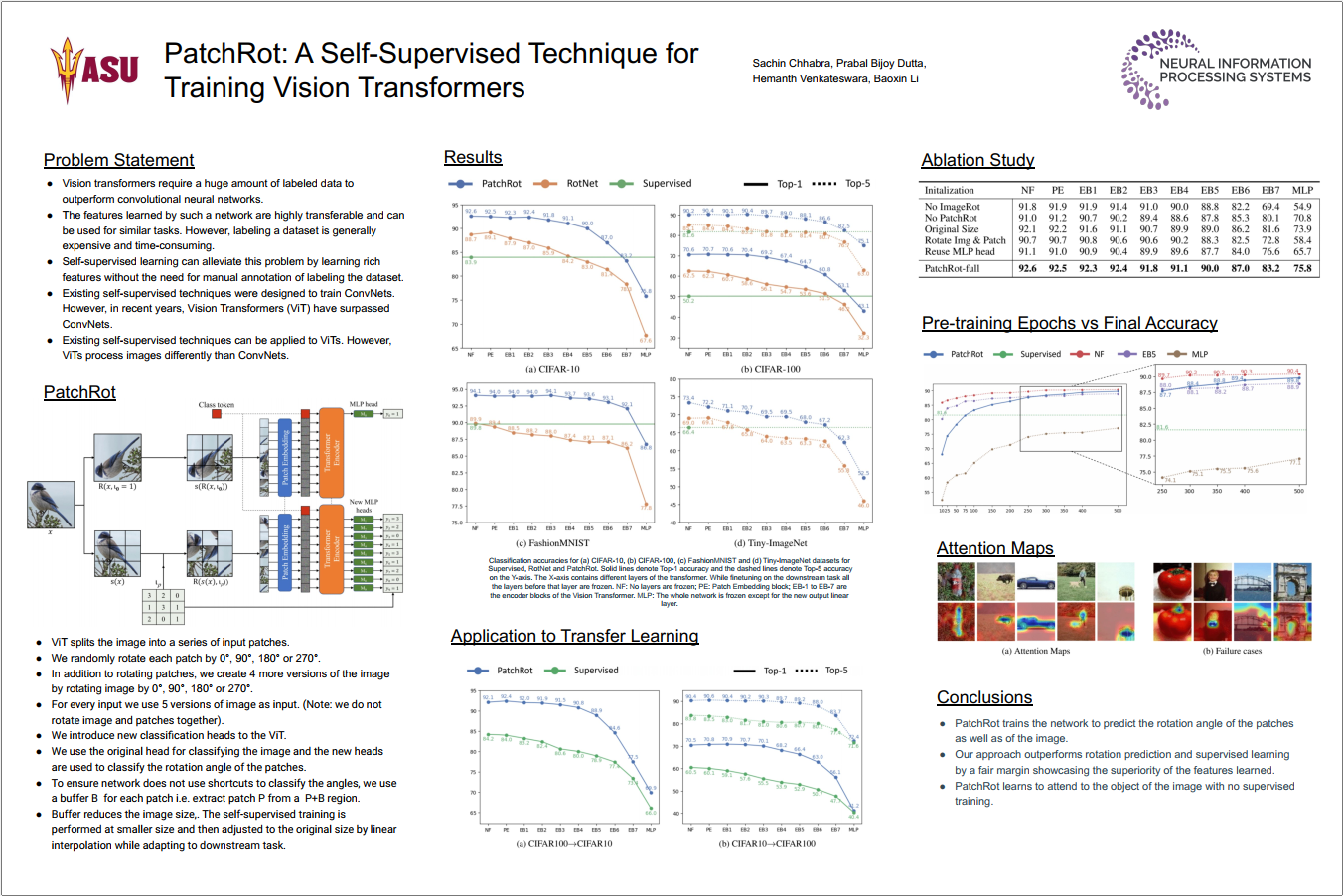
Vision transformers require a huge amount of labeled data to outperform convolutional neural networks. However, labeling a huge dataset is a very expensive process. Self-supervised learning techniques alleviate this problem by learning features similar to supervised learning in an unsupervised way. In this paper, we propose a self-supervised technique PatchRot that is crafted for vision transformers. PatchRot rotates images and image patches and trains the network to predict the rotation angles. The network learns to extract both global and local features from an image. Our extensive experiments on different datasets showcase PatchRot training learns rich features which outperform supervised learning and compared baseline.