Poster
in
Workshop: Workshop on Distribution Shifts: Connecting Methods and Applications
An Empirical Study on Distribution Shift Robustness From the Perspective of Pre-Training and Data Augmentation
Ziquan Liu · Yi Xu · Yuanhong Xu · Qi Qian · Hao Li · Rong Jin · Xiangyang Ji · Antoni Chan
{kind=link}
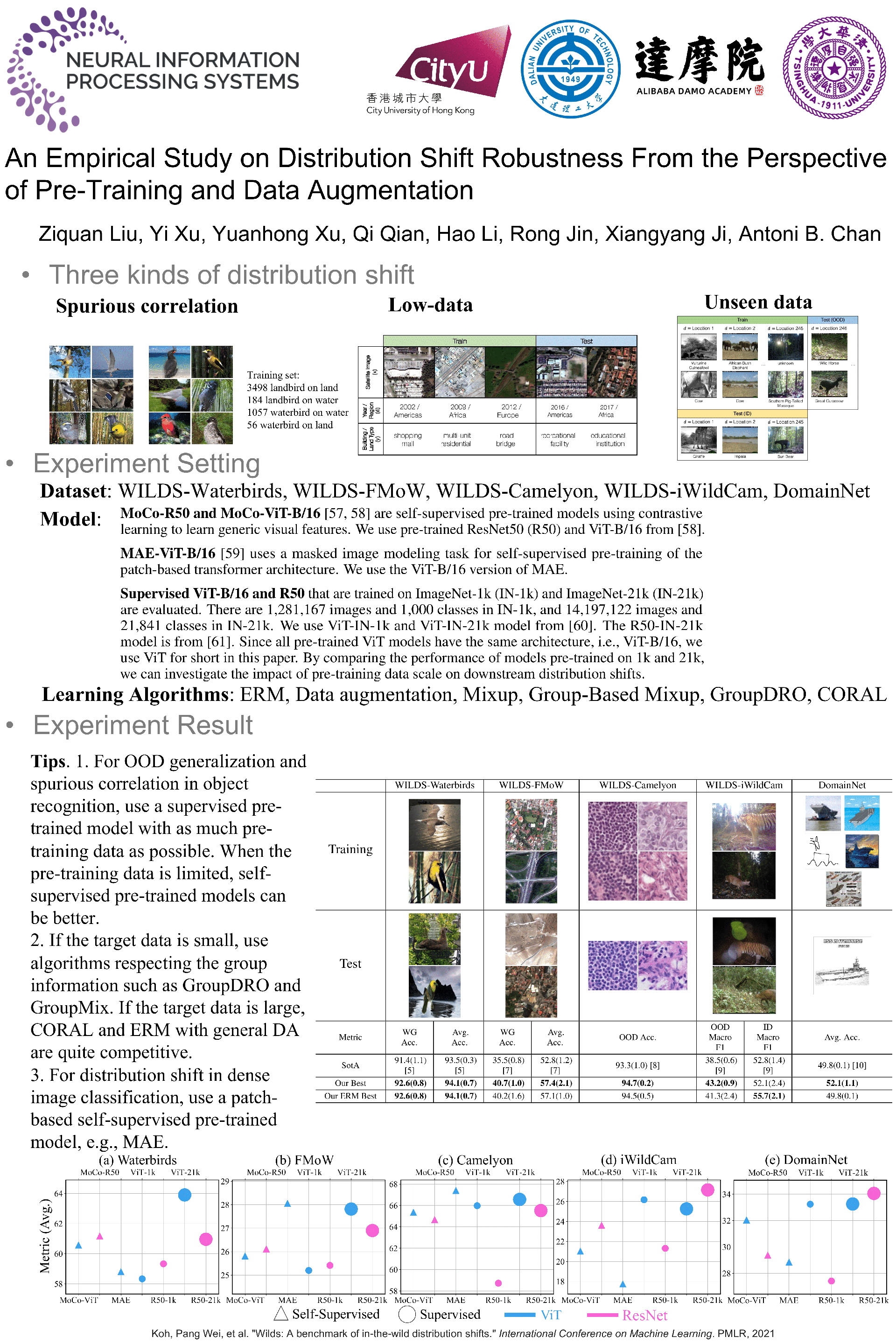
The performance of machine learning models under distribution shift has been the focus of the community in recent years. Most of current methods have been proposed to improve the robustness to distribution shift from the algorithmic perspective, i.e., designing better training algorithms to help the generalization in shifted test distributions. This paper studies the distribution shift problem from the perspective of pre-training and data augmentation, two important factors in the practice of deep learning that have not been systematically investigated by existing work. By evaluating seven pre-trained models, including ResNets and ViT's with self-supervision and supervision mode, on five important distribution-shift datasets, from WILDS and DomainBed benchmarks, with five different learning algorithms, we provide the first comprehensive empirical study focusing on pre-training and data augmentation. With our empirical result obtained from 1,330 models, we provide the following main observations: 1) ERM combined with data augmentation can achieve state-of-the-art performance if we choose a proper pre-trained model respecting the data property; 2) specialized algorithms further improve the robustness on top of ERM when handling a specific type of distribution shift, e.g., GroupDRO for spurious correlation and CORAL for large-scale out-of-distribution data; 3) Comparing different pre-training modes, architectures and data sizes, we provide novel observations about pre-training on distribution shift, which sheds light on designing or selecting pre-training strategy for different kinds of distribution shifts. In summary, our empirical study provides a comprehensive baseline for a wide range of pre-training models fine-tuned with data augmentation, which potentially inspires research exploiting the power of pre-training and data augmentation in the future of distribution shift study.