Poster
in
Workshop: LaReL: Language and Reinforcement Learning
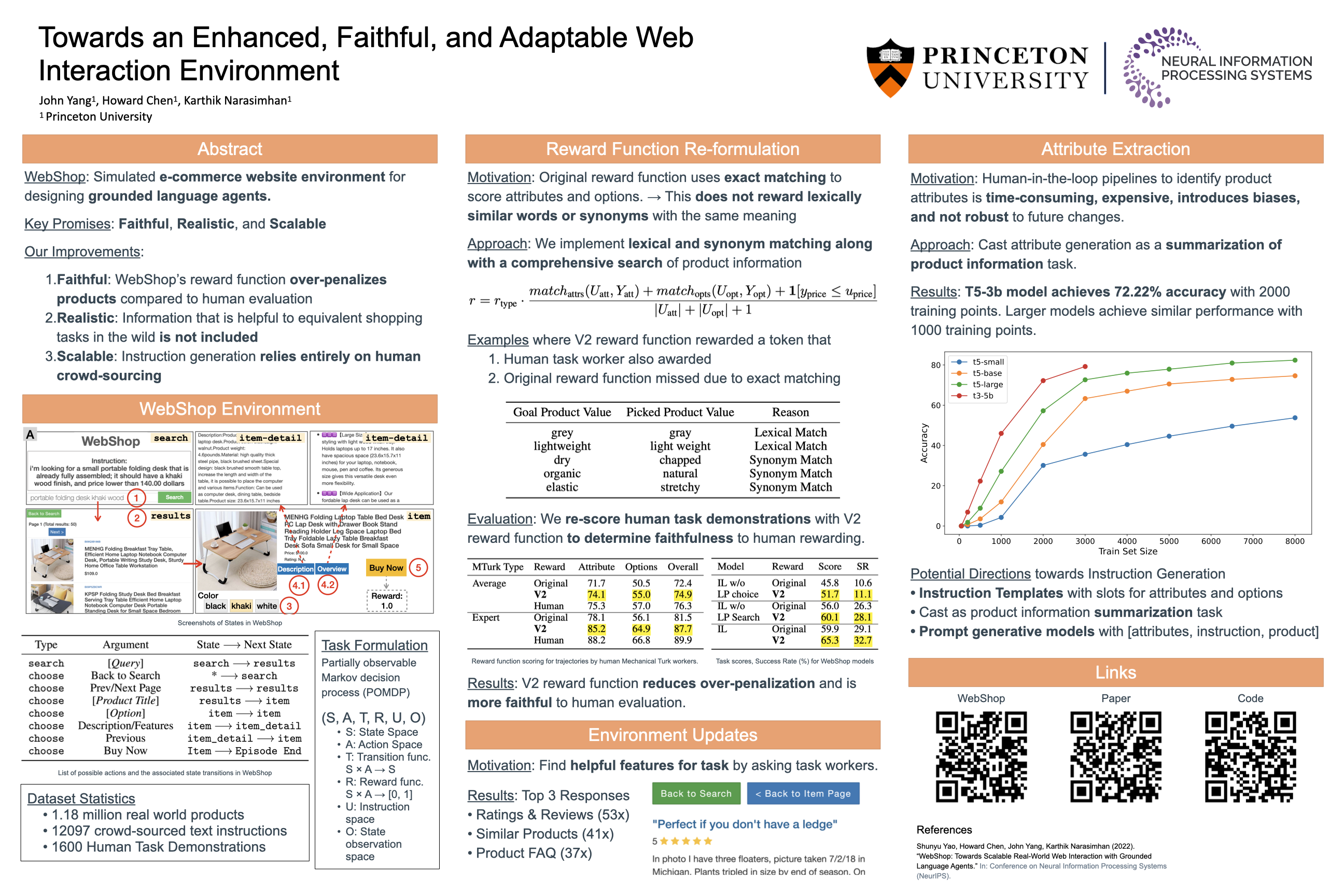
Towards an Enhanced, Faithful, and Adaptable Web Interaction Environment
John Yang · Howard Chen · Karthik Narasimhan
Keywords: [ web tasks ] [ sim-to-real transfer ] [ language grounding ] [ imitation learning ] [ Reinforcement Learning ] [ Natural Language Processing ]
{kind=link}
We identify key areas of improvement for WebShop, an e-commerce shopping environment for training decision making language agents. Specifically, shortcomings in: 1) faithfulness of the reward function to human evaluation, 2) comprehensiveness of its content, and 3) human participation required for generating instructions has hindered WebShop’s promises to be a scalable real-world environment. To solve these issues, we first incorporate greater faithfulness to human evaluation by designing a new reward function to capture lexical similarities and synonyms. Second, we identify customer reviews, similar products, and customer FAQs as missing semantic components that are most helpful to human execution of the task from surveying 75 respondents. Finally, we reformulate the attribute tagging problem as a extractive short-phrase prediction task to enhance scalability. Our V2 reward function closes the gap between the scores of the WebShop’s automated reward function (from 81.5% to 87.7%) and human evaluation (89.9%). Our attribute tagging approach achieves an accuracy of 72.2% with a t5-3b model fine tuned on 2, 000 training data points, showing potential to automate the instruction creation pipeline.