Poster
in
Workshop: Table Representation Learning
Structural Embedding of Data Files with MAGRITTE
Gerardo Vitagliano · Mazhar Hameed · Felix Naumann
Keywords: [ csv ] [ data preparation ] [ tabular data file ] [ structural embedding ]
{kind=link}
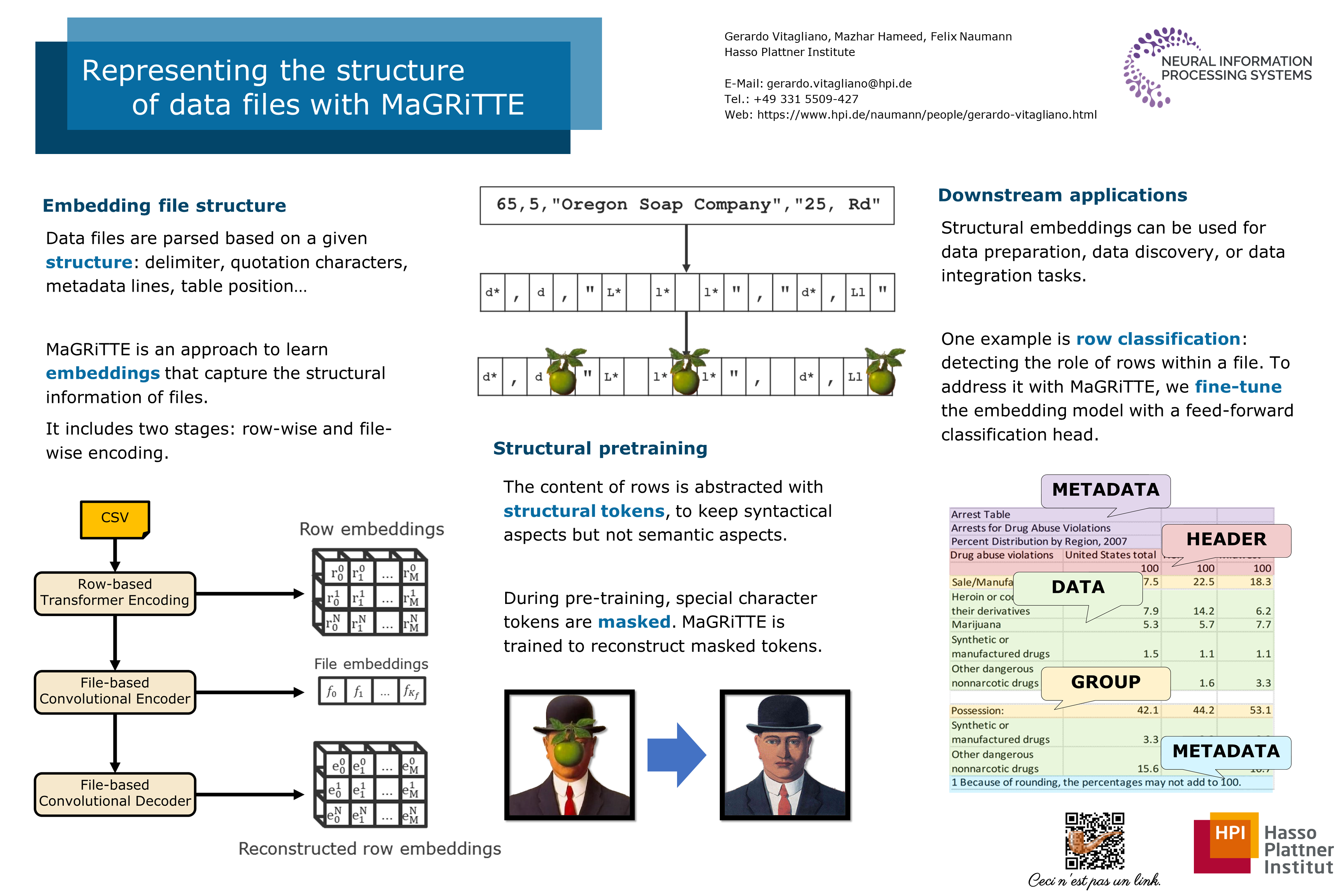
Large amounts of tabular data are encoded in plain-text files, e.g., CSV, TSV andTXT. Plain-text formats allow freedom of expression and encoding, fostering theuse of non-standard syntaxes and dialects. Before analyzing the content of suchfiles, it is necessary to understand their structure, e.g., recognize their dialect,extract metadata, or detect tables. Previous work on table representationfocused on learning the semantics of data cells , with the assumption thatthe syntactical properties of a file are known to end users.We propose MAGRiTTE, an approach to synthetically represent the structural featuresof a data file. MAGRiTTE is a self-supervised machine learning model trainedto learn structural embeddings from data files. The architecture of MAGRiTTEis composed of two components. The first is a transformer-encoder architecture,based on BERT and pre-trained to learn row embeddings. The second is aDCGAN-autoencoder trained to produce file-level embeddings. To pre-train thetransformer architecture on structural features, we propose two core adaptations: anovel tokenization stage and specialized training objectives. To abstract the datacontent of a file, and train the transformer architecture on structural features, we introduce“pattern tokenization”: Assuming that structural properties are identifiablethrough special characters, we reduce all alphanumeric characters to a set of fewgeneral patterns. After tokenization, the rows of the input files are split on newlinecharacters and a percentage of the special character tokens is masked before feedingit to the row encoder model. The row-transformer model is then trained on twoobjectives, reconstructing the masked tokens, and identifying whether pairs of rowsbelong to the same file. The row embeddings produced by this model are thenused as the input for the file embedding stage of MAGRiTTE. In this stage, thegenerator and discriminator models are trained in an adversarial fashion on the rowembeddings feature maps. To obtain a file-wise embedding vector, we concatenatethe output features produced from all convolutional stages of the discriminator.We shall evaluate the effectiveness of our learned structural representations on threetasks to analyze unseen data files: (1) fine-grained dialect detection, i.e., identifyingthe structural role of characters within rows, (2) line and cell classification, i.e.,identifying metadata, comments, and data within a file, (3) table extraction, i.e.,identifying the boundaries of tabular regions. We compare the use of MAGRiTTEencodings with state-of-the-art approaches that were specifically designed for thesetasks. In future work, we aim at using MAGRiTTE embeddings to automaticallyperform structural data preparation, e.g., extracting tables, removing unwantedrows, or changing file dialects.