Poster
in
Workshop: OPT 2022: Optimization for Machine Learning
Target-based Surrogates for Stochastic Optimization
Jonathan Lavington · Sharan Vaswani · Reza Babanezhad Harikandeh · Mark Schmidt · Nicolas Le Roux
{kind=link}
Abstract:
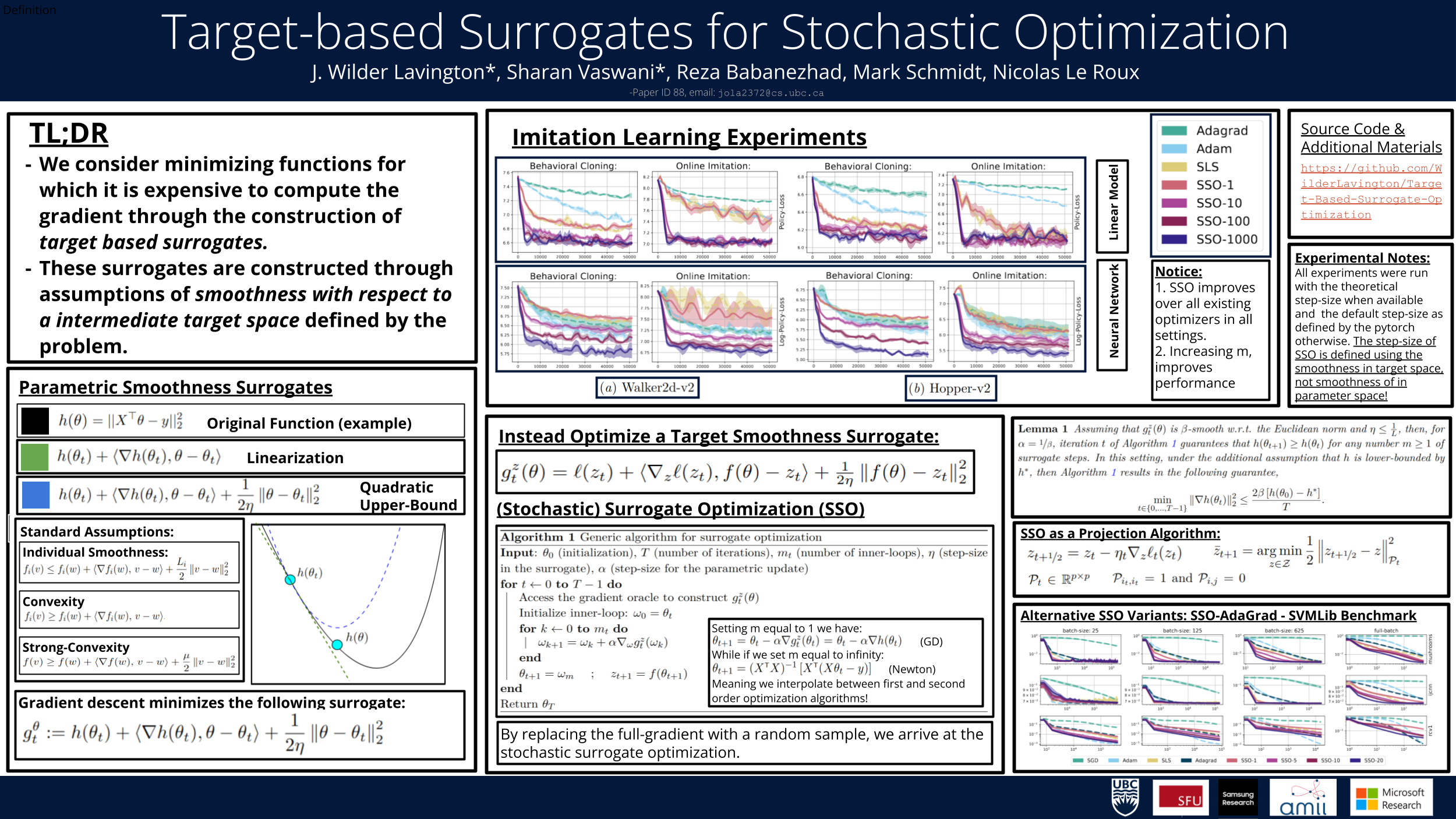
We consider minimizing functions for which it is computationally expensive to query the (stochastic) gradient. Such functions are prevalent in applications like reinforcement learning, online imitation learning and bilevel optimization. We exploit the composite structure in these functions and propose a target optimization framework. Our framework leverages the smoothness of the loss with respect to an intermediate target space (e.g. the output of a neural network model), and uses gradient information to construct surrogate functions. In the full-batch setting, we prove that the surrogate function is a global upper-bound on the overall loss, and can be (locally) minimized using any black-box optimization algorithm. We prove that the resulting majorization-minimization algorithm ensures convergence to a stationary point at an $O\left(\frac{1}{T}\right)$ rate, thus matching gradient descent. In the stochastic setting, we propose a stochastic surrogate optimization (SSO) algorithm that can be viewed as projected stochastic gradient descent in the target space. We leverage this connection in order to prove that SSO can match the SGD rate for strongly-convex functions. Experimentally, we evaluate the SSO algorithm on convex supervised learning losses and show competitive performance compared to SGD and its variants.
Chat is not available.